3D Mesh 生成
- NeuralNetworksSketchbook - github
- stable diffusion
- blender

- 格栅化反传
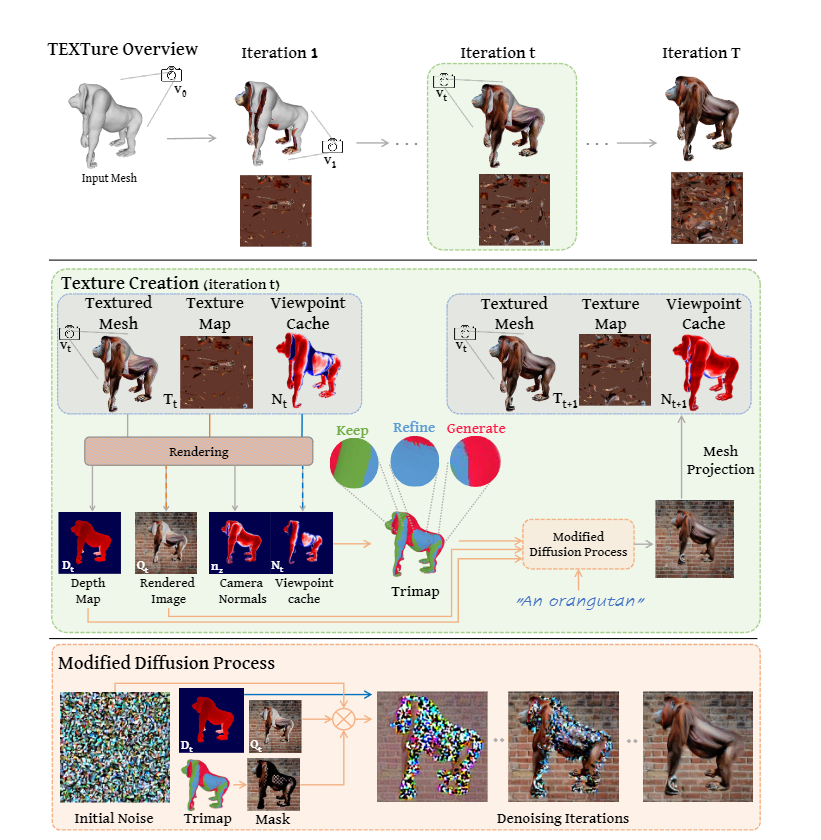
- TEXTure: Text-Guided Texturing of 3D Shapes
- iteration[“keep”, “refine”, “generate”]
- 多较多球面参数化,获得高清纹理
- Magic123 - One Image to High-Quality 3D Object Generation Using Both 2D and 3D Diffusion Priors
- 采用两阶段的3dmesh生成方法
- 第一阶段使用nerf生成粗糙的3d mesh表示
- 第二阶段用可微的神经网络对粗糙的3d mesh表示进行精细化
- 引入了2D和3D扩散先验的结合
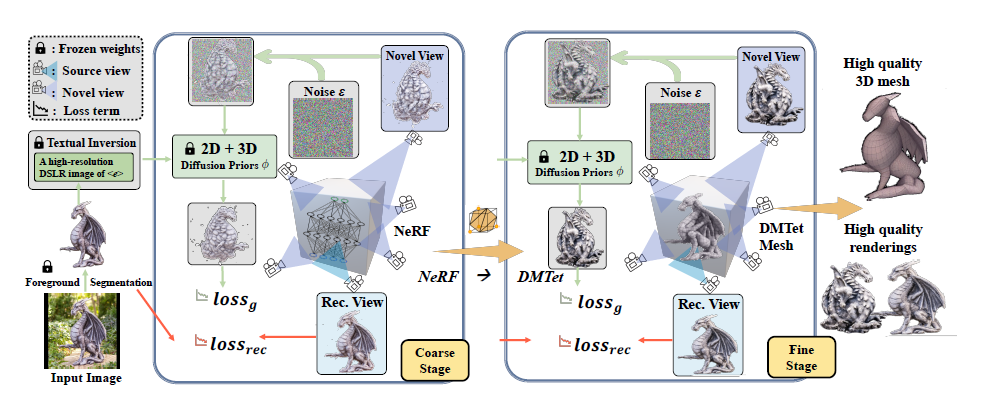
- 论文中提到了姿势化,姿势化是指目标物体或人体在图像中的姿势和表情。在一个单一的未指定姿势的图像中,姿势化是指通过计算机视觉技术和深度学习模型,从图像中推断出物体或人体的三维姿势和形状
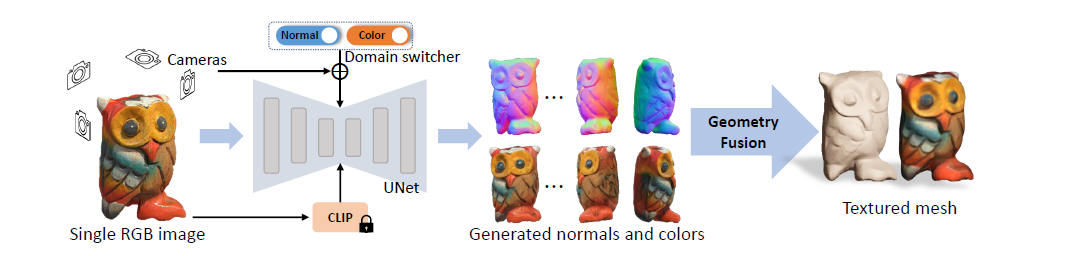
- Wonder3D: Single Image to 3D using Cross-Domain Diffusion

- 目前的3d生成任务,在面临多头一致性问题时,不管是边缝还是patch融合,作为一种后处理的方式,在基于nerf的求解框架下无法得到很好的解决,因此有很多基于2步的3d mesh和纹理生成任务的工作,但是这些工作都没有从根本上解决该问题,本论文提出了一种基于法向的mesh生成方案,在传统的mesh生成任务中,多头任务都是基于2d图片的,在2d图片中,法向信息被丢失,因此本文提出的wonder3d利用sd的扩散功能在生成2d images时,一并生成了对应角度的法向信息。同时,作者还引入了一种新颖的法线融合算法,可以从多视图的表示中提取出高质量的表面几何。
- Zero123: Zero-shot One Image to 3D Object
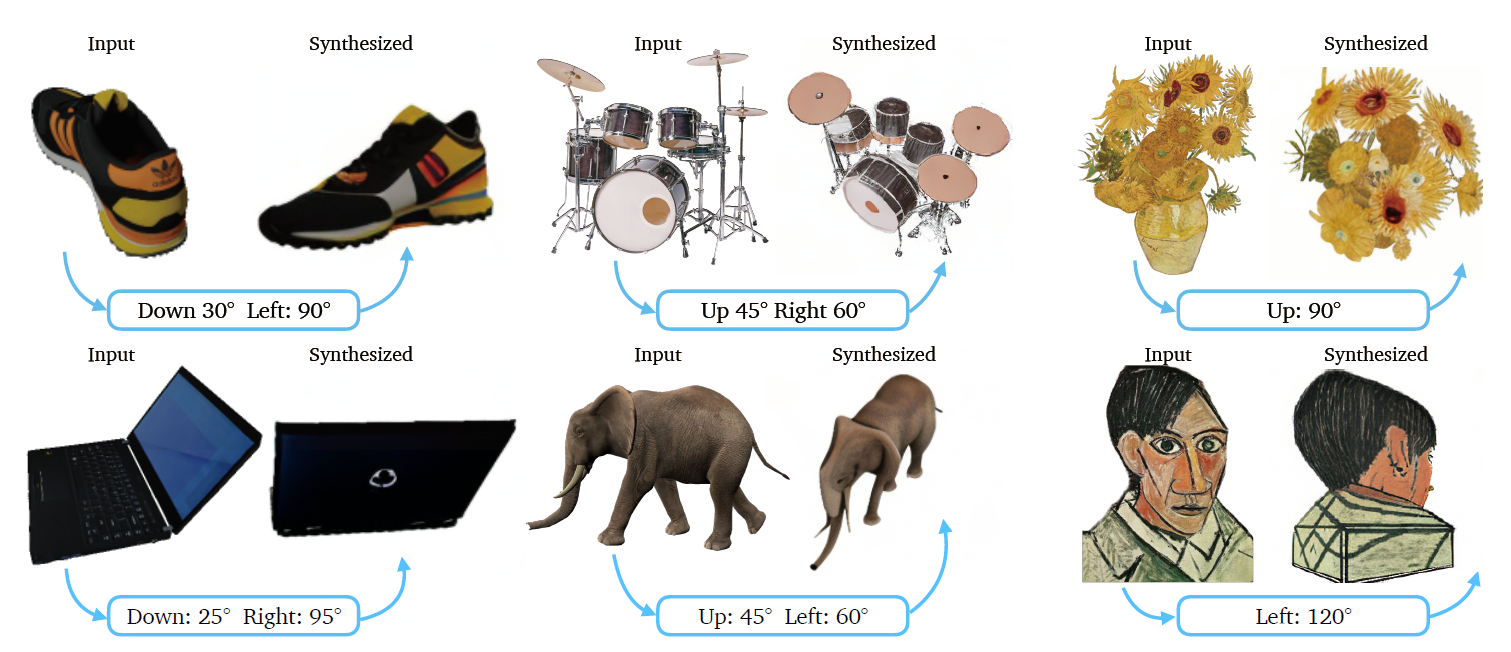
- 使用合成数据集训练一个具有先验知识的大模型,用于对单张图片进行多视角的预测
- 数据合成使用blender进行渲染
- 论文使用图片的相对视角进行合成
- 训练方法
- 算法目标,计算出合成图片$\hat{x}_{R,T}=f(x,R,T)$
- 训练输入,${(x, x_{(R,T),R,T})}$
- 其中,引入$c(x, R,T)$进行embedding:High-resolution image synthesis
with latent diffusion models
- 算法管道: txt->img->3d
- Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model

- 使用多视图的联合分布,而不是单张图片,以进行更加完整的一致性
- 改进了Condition,使用线性噪声表
- 利用Depth control net进行控制(好像不是特别明显的贡献)
- 主要对比了 zero123, zero123 xl, SyncDreamer
- SyncDreamer: Generating Multiview-consistent Images from a Single-view Image
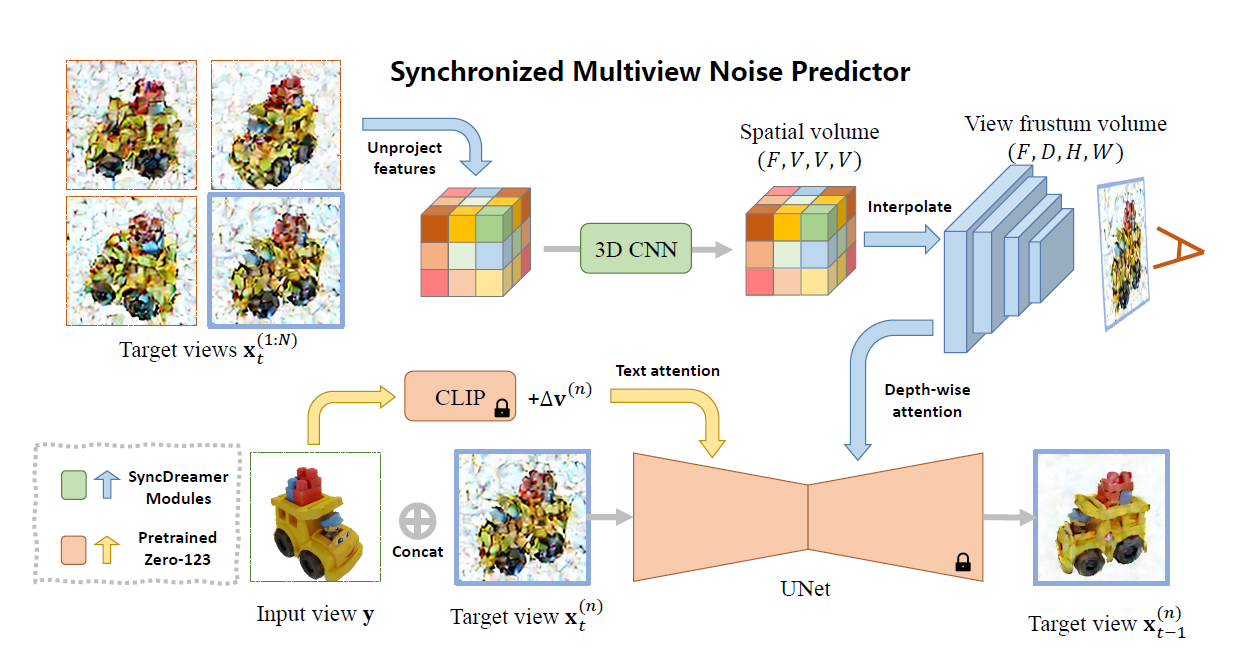
- 数据集
- 主要框架
- 使用目标视角进行通过unet训练,作者弄了个共享噪声预测器用于共享信息
- 在图像生成方面,主要使用了zero123的生成能力,上图黄色部分为zero的模型
- 论文好像水了一部分对比实验,在后文中,使用初始的stable diffusion进行对比,说效果比zero123差,额。。
- One-2-3-45: Any Single Image to 3D Mesh in 45 Seconds without Per-Shape Optimization
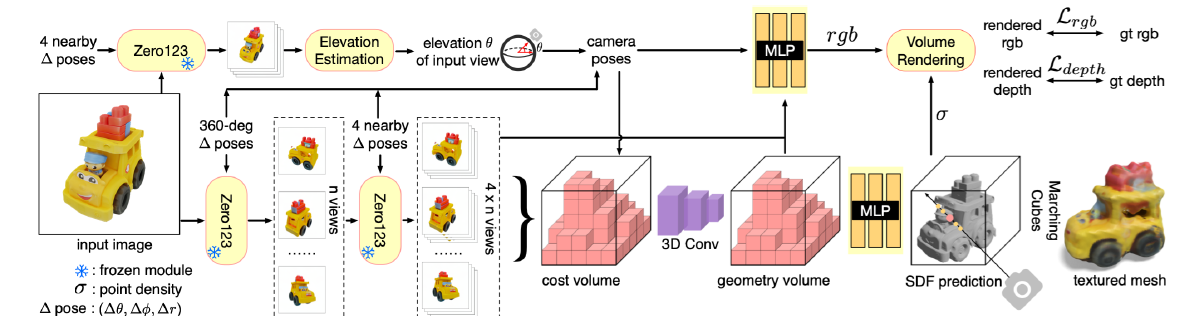
- 45秒左右将单个图像转换为高质量的360度纹理网格,无需进行形状优化
- 几何重建通过引入了SDF信息,进行几何估计,主要用到了相机视角加图片的方法进行体素估计,再转化为SDF,最后进行拍照比对
- 可以无缝地扩展到支持文本到3D的任务,为文本到网格生成等应用提供了可行的解决方案。
- 图片生成也主要依赖于zero123
- MVDREAM: MULTI-VIEW DIFFUSION FOR 3D GENERATION
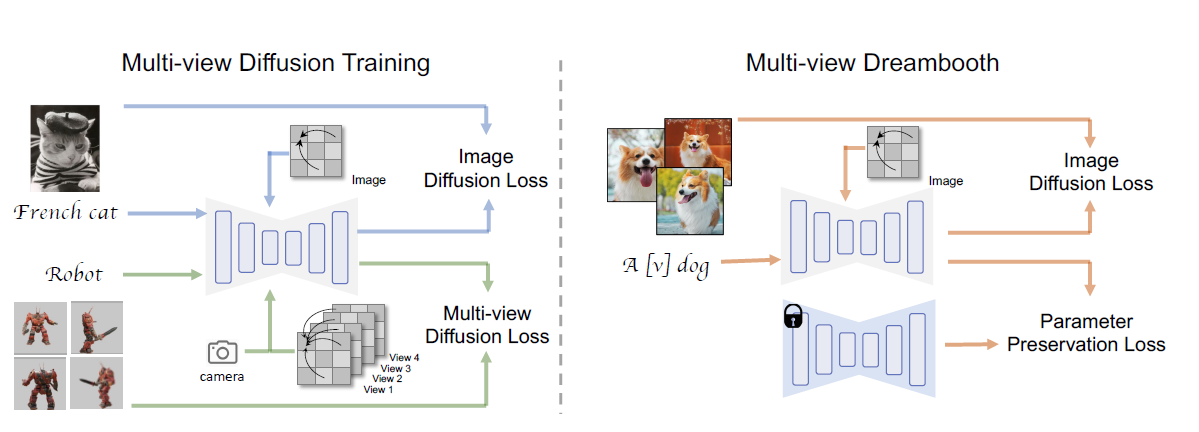
- 灵感:视频->3d
- 改进了现有的Score Distillation Sampling(SDS)方法
- SDS方法首先使用多视角扩散模型生成一组候选图像。然后,通过计算每个候选图像的分数,选择与输入文本条件最相匹配的候选图像
- 评分蒸馏采样 (SDS),它在参数空间而不是像素空间中进行采样
- ProlificDream使用变分评分蒸馏(Variational Score Distillation,VSD)
数据集
Reference