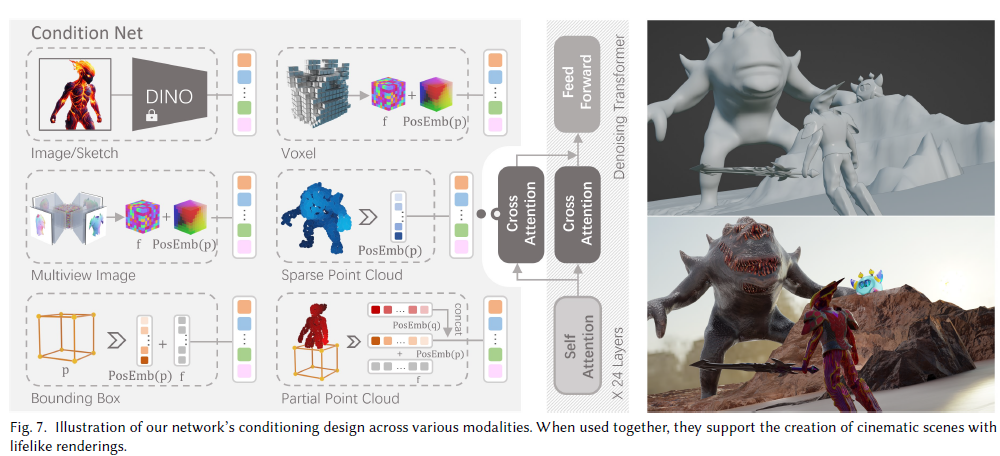
Pytorch Distributed Training Dataloader Test
How the dataloader split data into mutly devices
Code
from typing import List
import torch
from torch.distributed import init_process_group, get_rank
from torch.utils.data import Dataset, DataLoader, DistributedSampler
from tqdm import tqdm
class TestDataset(Dataset):
def __init__(self, size: int):
self.size = size
self.data: List[int] = list(range(size))
def __len__(self):
return self.size
def __getitem__(self, index):
return self.data[index]
init_process_group(backend="nccl")
rank = get_rank()
torch.cuda.set_device(rank)
device = torch.device("cuda", rank)
BATCH_SIZE = 1
dataset = TestDataset(3)
loader = DataLoader(dataset, batch_size=BATCH_SIZE, num_workers=0, drop_last=True,
sampler=DistributedSampler(dataset, shuffle=True)
)
bar = tqdm(enumerate(loader, 0), leave=True, total=len(loader), position=0, disable=True)
for i, data in bar:
print((rank, i, data.cuda()))
Command
PYTHONUNBUFFERED=1;CUDA_VISIBLE_DEVICES=0,7;OMP_NUM_THREADS=1;CUDA_LAUNCH_BLOCKING=0
-u -m torch.distributed.run --nproc_per_node=2
Result
-
size = 1
-
(rank:0, i:0, tensor([0], device='cuda:0')) (rank:1, i:0, tensor([0], device='cuda:1'))
-
-
size = 2
-
(rank:0, i:0, tensor([0], device='cuda:0')) (rank:1, i:0, tensor([1], device='cuda:1'))
-
-
size = 3
-
means pytorch will pick enough data to fill a batch
-
(rank:0, i:0, tensor([2], device='cuda:0')) (rank:0, i:1, tensor([1], device='cuda:0')) (rank:1, i:0, tensor([0], device='cuda:1')) (rank:1, i:1, tensor([2], device='cuda:1'))
-
Comment
- here the data model will not synchronism
DDP
import random
from typing import List
import torch
import numpy as np
from torch import distributed, optim, nn, Tensor
from torch.distributed import init_process_group, get_rank
from torch.nn.parallel import DistributedDataParallel
from torch.utils.data import Dataset, DataLoader, DistributedSampler
from tqdm import tqdm
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.use_deterministic_algorithms(True)
def reduce_tensor(tensor: torch.Tensor) -> torch.Tensor:
rt = tensor.clone()
distributed.all_reduce(rt, op=distributed.ReduceOp.SUM)
rt /= distributed.get_world_size()
return rt
class TestModule(nn.Module):
def __init__(self, x: Tensor):
super().__init__()
self.x = nn.Parameter(x)
def forward(self, u: Tensor):
return torch.norm(u - self.x, 2)
class TestDataset(Dataset):
def __init__(self, size: int):
self.size = size
self.data: List[int] = list(range(size))
def __len__(self):
return self.size
def __getitem__(self, index):
return self.data[index]
init_process_group(backend="nccl")
rank = get_rank()
torch.cuda.set_device(rank)
device = torch.device("cuda", rank)
BATCH_SIZE = 1
SEED = 42
setup_seed(SEED)
dataset = TestDataset(2)
loader = DataLoader(dataset, batch_size=BATCH_SIZE, num_workers=2, drop_last=True,
sampler=DistributedSampler(dataset, shuffle=True)
)
bar = tqdm(enumerate(loader, 0), leave=True, total=len(loader), position=0, disable=True)
total = torch.tensor(0.).cuda()
x = torch.Tensor([0.]).cuda()
model = TestModule(x)
model = DistributedDataParallel(model)
optimizer = optim.Adam(model.parameters(), lr=.1)
for i, data in bar:
num = data.cuda()
if rank == 0:
# will lead the tensor reduce hangs
continue
loss = model(num)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total += loss.sum()
total_reduce = reduce_tensor(total)
print(x)
print(total_reduce)
PYTHONUNBUFFERED=1;CUDA_VISIBLE_DEVICES=0,7;OMP_NUM_THREADS=1;CUDA_LAUNCH_BLOCKING=0
-u -m torch.distributed.run --nproc_per_node=2
About reduce api
all_reduce(x, op=ReduceOp.SUM, async_op=True)
# Here async_op 表示同步还是异步,default as False
# 如果是异步,则不同的进程得到的结果是不同的
init_process_group(backend="nccl")
rank = get_rank()
torch.cuda.set_device(rank)
device = torch.device("cuda", rank)
item_inner = torch.tensor(1.).cuda()
item_outer = torch.tensor(1.).cuda()
# print((rank, x))
if rank == 0:
time.sleep(10)
op_outer = all_reduce(item_outer, async_op=True)
# 隐式变量依然可以保持同步
op_inner = all_reduce(item_inner, op=ReduceOp.SUM, async_op=True)
op_inner.wait()
# 如果op_inner已完成等待,则op_outer也已完成reduce计算
# 反之op_outer已完成等待,op_inner未必完成计算
print((rank, item_inner.item()))
print((rank, item_outer.item()))
Reference
- [原创][深度][PyTorch] DDP系列第一篇:入门教程 - 996黄金一代的文章 - 知乎
- [原创][深度][PyTorch] DDP系列第二篇:实现原理与源代码解析 - 996黄金一代的文章 - 知乎
- [原创][深度][PyTorch] DDP系列第三篇:实战与技巧 - 996黄金一代的文章 - 知乎
- Zhiyuan Chen - zyc.ai
- Best practice for uneven dataset sizes with DistributedDataParallel - discuss.pytorch.org
- Support uneven DDP inputs - github.com
- Hook