Pytorch Multi GPU
单机多卡
Priori Knowledge
- Pytorch 1.x 的多机多卡计算模型
- Uber: Horovod, Baidu: RingAllReduce
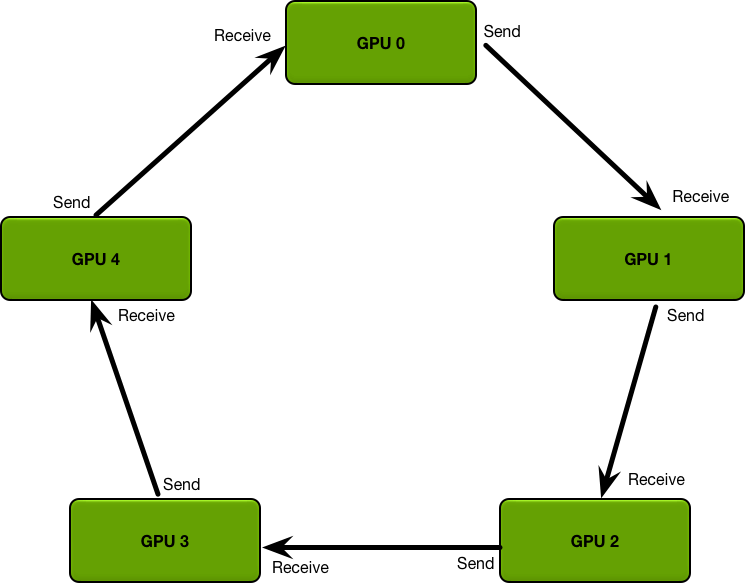
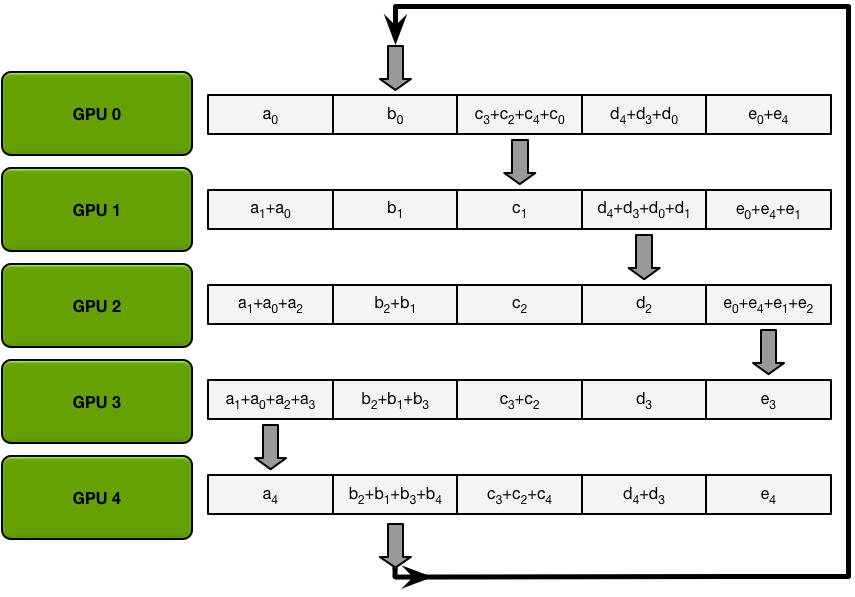
- PS 计算模型
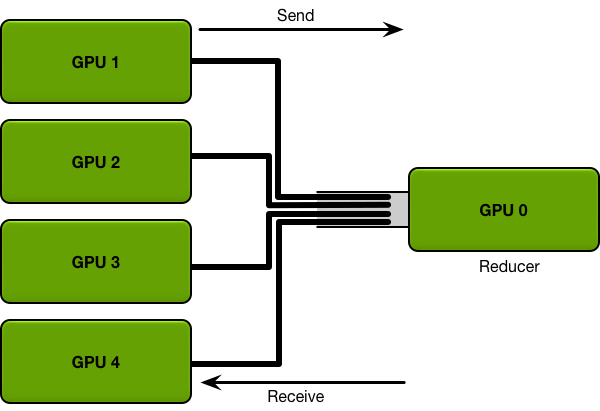
DataParallel [DP]
- dataset:
FashionMNIST - Main Code
DataParallelParameter server算法-
reducer的那张卡会多出3-4g的显存占用
# Model
net = nn.DataParallel(net)
net = net.cuda()
# Data
inputs = inputs.cuda()
labels = labels.cuda()
| Params | Speed | Mem% |
|---|---|---|
| CUDA_VISIBLE_DEVICES=3 | 15000it [00:55, 271.38it/s] | 3:7-13 |
| CUDA_VISIBLE_DEVICES=3,4,6 | 15000it [01:48, 138.19it/s] | 3:4-7,4:3-5,6:0 |
| CUDA_VISIBLE_DEVICES=2,3,4 | 15000it [01:50, 134.29it/s] | 2:4-7,3:3-5,4:0 |
| CUDA_VISIBLE_DEVICES=0,1,2,3 | 15000it [02:59, 83.67it/s] | 0,1,2,3:2-3 |
| CUDA_VISIBLE_DEVICES=1,2,3,4,6 | 15000it [02:28, 101.34it/s]] | 1:4-6,2,3,4:2-4,6:0 |
| CUDA_VISIBLE_DEVICES=6 | CUDNN_STATUS_NOT_INITIALIZED | |
| CUDA_VISIBLE_DEVICES=3,6 | CUDNN_STATUS_NOT_INITIALIZED |
CUDNN_STATUS_NOT_INITIALIZED- Gpu 内存未释放,但未使用,存在僵尸进程
fuser -v /dev/nvidia*to check all pid with this devicefuser -k /dev/nvidia6kill all processes that using the device nvidia6- But it will kill all other processes too
DistributedDataParallel [DDP]
torch.distributed.get_rank()- 获得进程号
-
--nproc_per_node=2时,两个进程的rank是不一样的rank = torch.distributed.get_rank() torch.cuda.set_device(rank) # 重要 inputs = inputs.cuda() if i == 0: # 不同的进程会把不同的数据放到不同的GPU上 # DataLoader 的 sampler处理这一逻辑 # 因此batch速度会加快 print(inputs.sum()) # tensor(-1578.1804, device='cuda:0'), tensor(-1578.1804, device='cuda:0')
-
保存参数 (只需要在一台机器上执行一次)
if dist.get_rank() == 0: torch.save(model.module, "saved_model.ckpt") - main code
net = net.cuda()
net = nn.parallel.DistributedDataParallel(net)
...
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=4,
num_workers=2,
sampler=DistributedSampler(trainset, shuffle=True))
testloader = torch.utils.data.DataLoader(testset,
batch_size=4,
num_workers=2,
sampler=DistributedSampler(testset, shuffle=False))
nproc_per_node: node
| Speed | CUDA | LOCAL_RANK | OMP | node | Mem% | epoch | Loss |
|---|---|---|---|---|---|---|---|
| 7500it [00:32, 229.33it/s]*2 | 0,3,5,6 | 0 | 1 | 2 | 0,3:7-13 | 1 | 0.4727 |
| 3750it [00:17, 210.65it/s]*4 | 0,3,5,6 | 0 | 1 | 4 | 0,3,5,6:17-30 | 1 | 0.6172 |
| 7500it [00:32, 228.66it/s]*2 | 0,3 | 0 | 1 | 2 | 0,3:17-30 | 1 | 0.4878 |
| 15000it [01:00, 210.65it/s] | 0,3,5,6 | 0 | 1 | 1 | 0:17-30 | 1 | 0.4165 |
| 7500it [00:32, 228.66it/s]*4 | 0,3,5,6 | 0 | 1 | 2 | 0,3:17-30 | 2 | 0.3774 |
| 3750it [00:25, 149.55it/s]*16 | 0,3,5,6 | 0 | 1 | 4 | 0,3,5,6:17-30 | 4 | 0.3563 |
多机多卡
- nnodes
- 机器数
- node_rank
- 当前机器序号
- nproc_per_node
- 每台机器上进程数
- address, port
- 通讯地址及端口
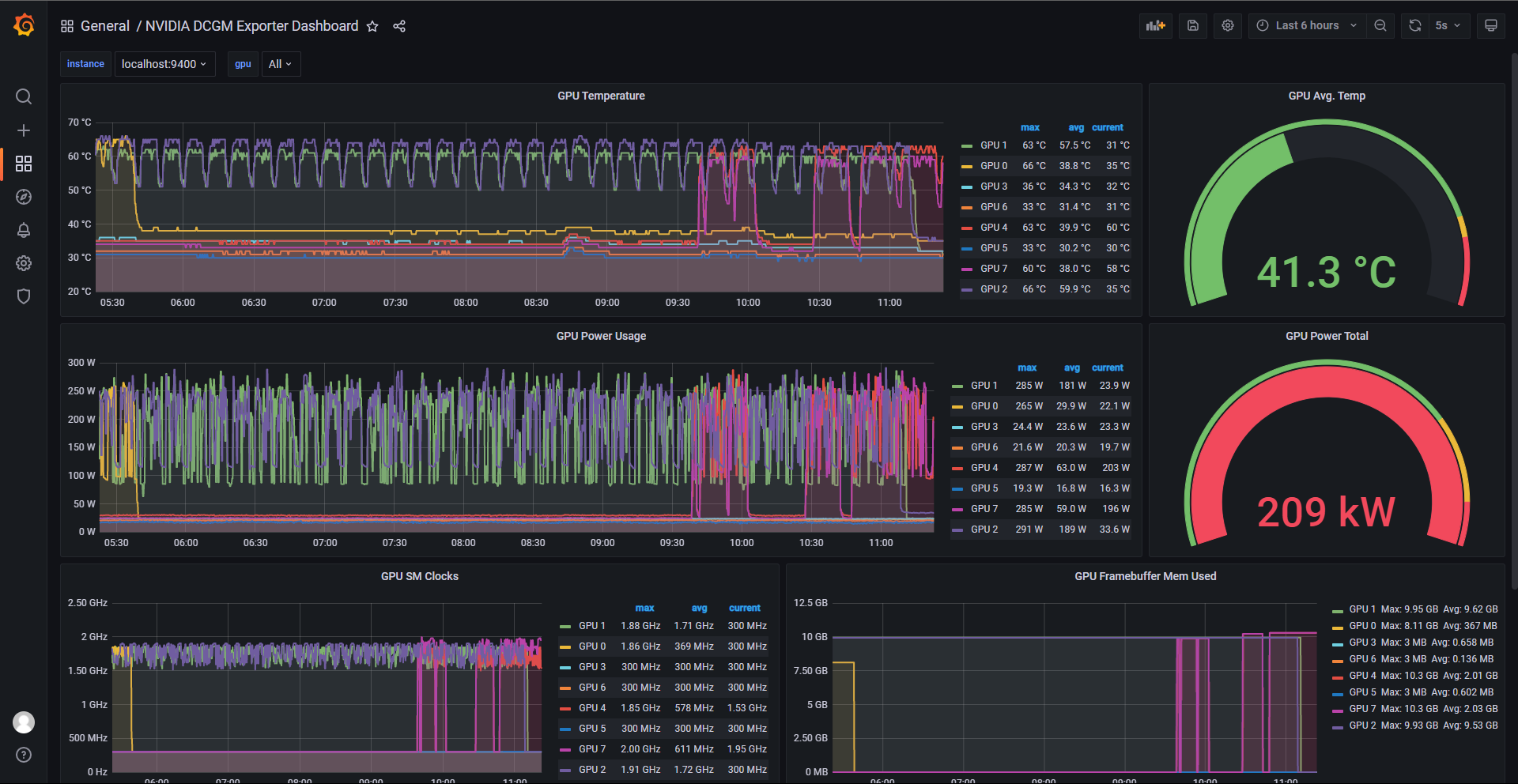
Gpu Monitor
- Github - NVIDIA/gpu-monitoring-tools
- deprecated at August 2021
- NVIDIA/dcgm-exporter
-
Repository spark star 

-
DCGM_EXPORTER_VERSION=2.1.4-2.3.1 && docker run -d --rm --gpus all --net host --cap-add SYS_ADMIN nvcr.io/nvidia/k8s/dcgm-exporter:${DCGM_EXPORTER_VERSION}-ubuntu20.04 -f /etc/dcgm-exporter/dcp-metrics-included.csv
-
- Prometheus
- config
- job_name: 'gpu' scheme: 'http' metrics_path: '/metrics' static_configs: - targets: - 'localhost:9400' - Grafana
- Fish
sudo apt install fishchsh -s /usr/bin/fishchange default bash to fishconda init fishatbashconda config --set auto_activate_base true, auto activate base