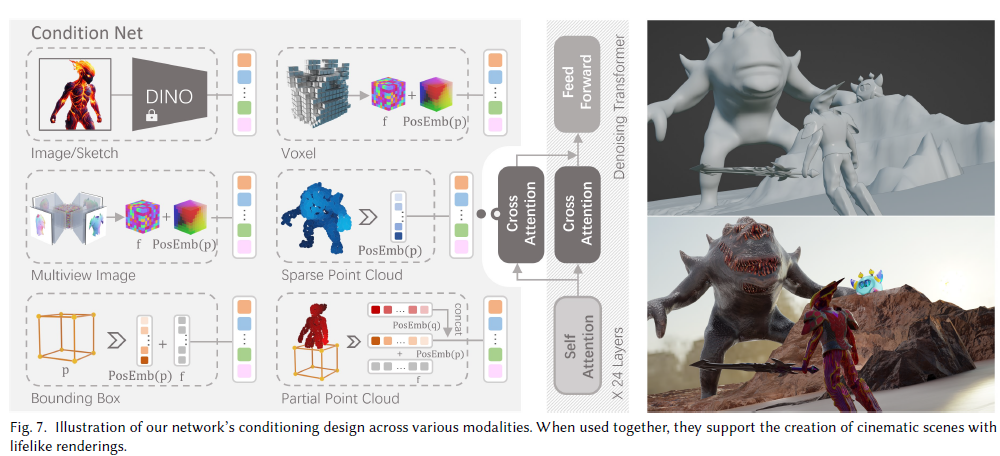
Lora
Introduction
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- 论文的基本假设,对于一个大模型,参数的秩通常是满的,但是对于一个特定领域的微调模型,存在一个更低维度的秩,使得模型可以适配于特定领域。因此,对于微调的模型,可以通过Lora的方式来训练
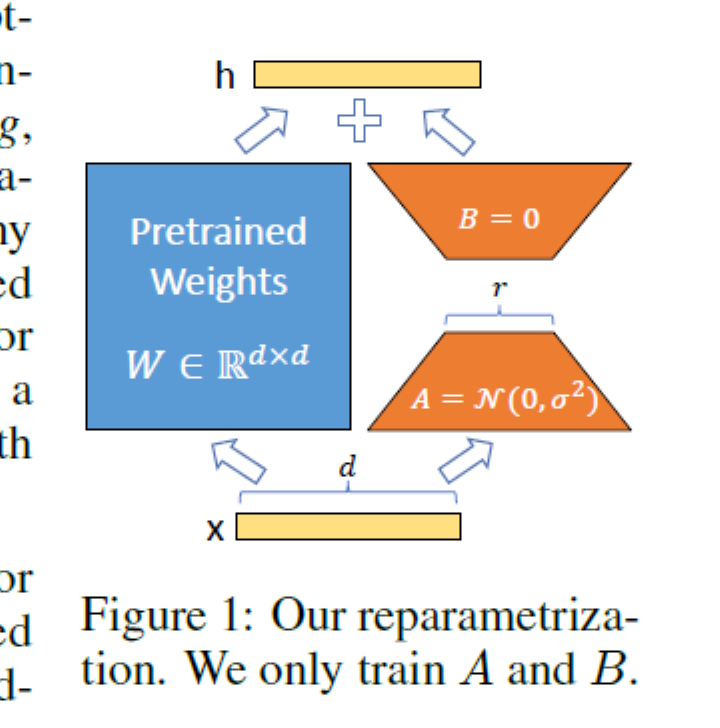
- 其基本公式$W=W_0+\Delta W=W_0+BA$
- 其中$B\in\reals^{d\times r},A\in\reals^{r\times k}$
- 秩$r\llless\min(d, k)$
- 对于$h=W_0x+\Delta Wx=W_0x+BAx$
- 只需要适当训练BA即可
- 其中A使用随机高斯初始化,B使用0初始化,因此,训练开始时$BA=0$
- 该算法可以应用到大部分矩阵,例如对于Transformer[QKVO]