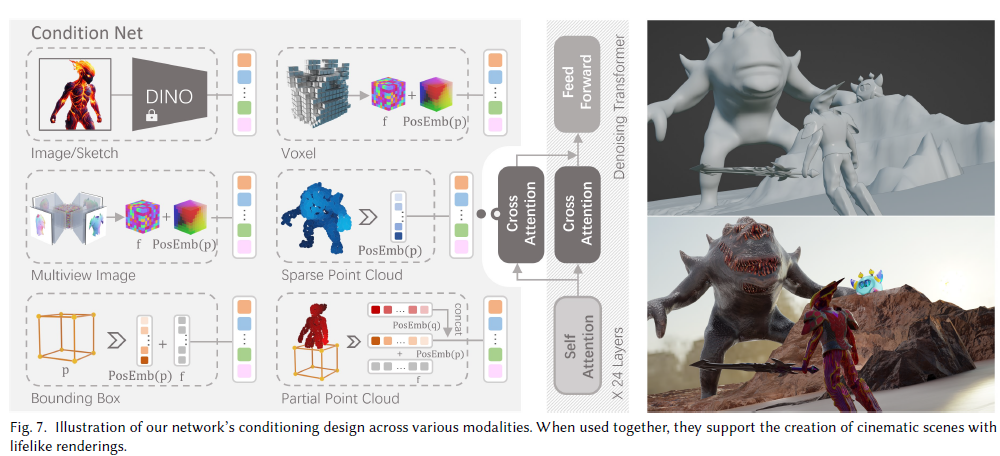
VQ-VAE
VQ-VAE
| Model | Stage-1 (latent space learning) | Latent Space | Stage-2 (prior learning) |
|---|---|---|---|
| VQ-VAE | VQ-VAE | Discrete (after quantization) | Autoregressive PixelCNN |
| VQGAN | VQGAN (VQ-VAE + GAN + Perceptual Loss) | Discrete (after quantization) | Autoregressive GPT-2 (Transformer) |
| VQ-Diffusion | VQ-VAE | Discrete (after quantization) | Discrete Diffusion |
| Latent Diffusion (VQ-reg) | VAE or VQGAN | Continuous (before quantization) | Continuous Diffusion |
- AE学习得到的隐空间并不规整
-
AE(Autoencoder,自编码器)是一种无监督学习模型,由编码器(Encoder)和解码器(Decoder)组成。编码器将输入数据映射到一个通常维度更低的隐空间(latent space),解码器则从隐空间重构出原始输入。AE的目标是最小化重构误差,即输入和重构输出之间的差异。
-
当我们说AE的编码器编码出来的向量空间是不规整的,主要是指以下几个方面:
- 空间分布不均匀:隐空间中的数据点分布可能不均匀,某些区域的数据点密度可能很高,而其他区域的数据点稀疏。这可能导致生成的样本质量不稳定。
- 空间缺乏连续性:相似的输入数据点在隐空间中可能不会映射到相近的位置,空间的连续性不够平滑。这意味着在隐空间中进行插值或采样可能生成质量较差的样本。
- 空间缺乏解释性:隐空间中的维度可能没有明确的语义解释,不同维度的变化对输入数据的影响难以解释。这限制了我们对隐空间的理解和控制。
- 空间缺乏结构性:隐空间可能没有明显的层次结构或规律性,不同类别的数据在隐空间中可能混杂在一起,缺乏清晰的分类边界。
-
VQ-VAE 目标
- 编码器(Encoder):将输入数据x映射到一个连续的隐空间,得到隐变量z。与普通VAE不同的是,VQ-VAE希望z是离散的。
- 矢量量化(Vector Quantization):引入一个离散的码本e,它包含K个D维的码字向量ek。隐变量z通过与码本中每个码字计算L2距离,找到最近的码字ek,并用其替代原始的z。这个量化过程使得隐变量离散化。
- 解码器(Decoder):将量化后的隐变量ek作为输入,重构出原始数据x。
- 训练目标:VQ-VAE优化三个损失函数: (1)重构损失:衡量重构数据与原始数据的差异; (2)码字向量关于隐变量z的损失:使编码器产生的隐变量接近码本中的码字向量; (3)码本的损失:通过优化码本,使码字向量能够捕捉到数据的局部特征。
缺点
- 量化操作不可导:在训练过程中,VQ-VAE的量化操作是不可导的,这使得端到端的梯度反向传播变得困难。通常需要使用一些梯度估计技巧如Straight-Through Estimator来绕开这个问题,但这可能影响模型的优化和收敛速度。
- 码本大小的选择:VQ-VAE中码本的大小K是一个需要提前设定的超参数。K的选择会影响模型的表示能力和计算复杂度。K太小,码本可能无法充分捕捉数据的多样性;K太大,则会增加计算开销,并可能导致某些码字向量无法得到有效利用。
- 码字利用率不平衡:在训练过程中,某些码字向量可能被频繁使用,而另一些却很少被用到。这导致码本的利用率不平衡,某些码字向量可能冗余。需要引入额外的机制如码本损失或指数移动平均来缓解这个问题。
- 隐变量的独立性假设:VQ-VAE假设隐变量之间是独立的,忽略了它们之间可能存在的结构或关系。这限制了模型捕捉某些复杂数据的能力。一些后续工作如VQ-VAE-2尝试通过引入分层结构来缓解这个问题。
- 生成多样性不足:相比一些其他生成模型如GAN,VQ-VAE的生成结果可能缺乏多样性和细节。这可能是因为离散隐变量的表示能力有限,以及解码器网络结构的限制。
- 适用范围有限:VQ-VAE更适用于那些需要离散特征表示的任务,如语音识别、语言建模等。对于一些需要连续潜在表示的任务,普通的VAE可能更合适。
- Perplexity值越高,说明模型使用的unique codebook向量越多,codebook的利用率就越高。这通常意味着模型能够从数据中学习到更丰富的表示。
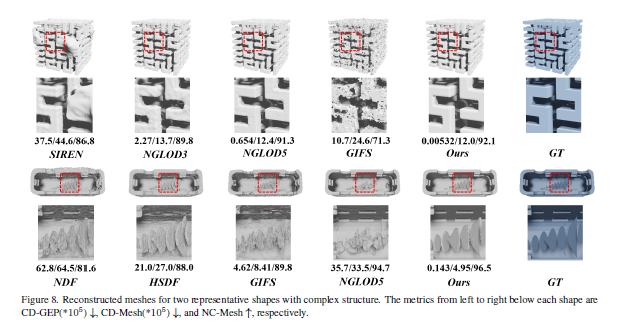
VQ-VAE-2
我们知道自回归模型的一大缺点是生成速度慢,这是因为一张高清图像的像素成千上万,而自回归模型只能串行生成一个个像素。为了解决这个问题,我们可以把自回归模型放到隐空间去,这样不仅速度成倍加快,信息密度也更高——像素空间中冗余繁杂的细节信息被压缩掉了,模型只需要考虑真正重要的语义信息。
- 整体架构:
- 第一阶段是训练层次化的VQ-VAE编码器和解码器:
- 编码器由多个下采样块组成,将输入图像逐步编码为离散的潜码。第一个编码器先将图像编码为较低层次的潜码(如 64x64),然后第二个编码器在此基础上继续编码为更高层次的潜码(如32x32)。不同层次的编码器通过残差连接组合在一起。
- 解码器采用与编码器相反的结构,由多个上采样块组成。它以多个层次的离散潜码为输入,通过解码和上采样,逐步重建出原始图像。
- 整个VQ-VAE的训练目标是最小化重建误差,同时使用一些正则项如codebook loss和commitment loss来优化离散潜码的学习。
- 第二阶段是在学习到的离散潜码空间上训练强大的自回归先验模型:
- 先将所有图像通过训练好的VQ-VAE编码器编码为离散潜码,构建新的训练集。
- 在低层次的潜码(如64x64)上训练一个conditional PixelCNN先验模型,将高层次潜码(如32x32)作为条件输入。
- 在高层次潜码上训练一个无条件的PixelCNN先验模型。为了捕捉长距离依赖,该先验模型中使用了self-attention层。
- 最终的图像生成过程为:先通过高层次的PixelCNN采样高层潜码,再将其作为条件输入到底层PixelCNN中采样底层潜码。然后将采样得到的多个层次的潜码输入到VQ-VAE解码器中解码,得到最终的图像。
- 第一阶段是训练层次化的VQ-VAE编码器和解码器:
- 优点:
- 通过使用分层的离散潜变量表示,VQ-VAE-2可以生成高质量、高分辨率的图像样本,其效果可以与最先进的GAN模型相媲美。
- VQ-VAE-2使用简单的前馈编码器和解码器网络,编码和解码速度很快。相比直接在像素空间采样,VQ-VAE-2只需要在压缩后的潜码空间进行自回归采样,速度提高了一个数量级。
- VQ-VAE-2可以很好地捕捉数据分布的所有模式,生成样本的多样性优于GAN。不会出现GAN常见的模式坍塌问题。
- 不同于GAN难以评估,VQ-VAE-2作为一个似然性模型,可以通过测试集上的似然性来客观评估泛化能力,监控过拟合情况。
- 缺点:
- VQ-VAE-2的重建图像会丢失一些高频细节信息,因此FID等指标比实际感知质量要差一些。
- 尽管VQ-VAE-2的采样速度比像素空间快很多,但是其自回归先验模型的训练仍然是个瓶颈,在大规模高分辨率数据集上训练需要巨大的计算开销。
- VQ-VAE-2涉及两个阶段的训练,先训练VQ-VAE再训练先验模型,流程稍显复杂。端到端训练可能会进一步提升性能。
- 为了提高样本质量,本文还提出了基于分类器的拒绝采样等附加技巧,一定程度上削弱了似然性模型的优势。
- QA
- 为什么要用自回归函数
- 自回归函数可以建模更长距离的依赖关系。如果只依赖周围8个像素,CNN的感受野很小,只能捕捉到局部的相关性。而图像中存在很多长程依赖,如物体的整体结构、重复的纹理等。自回归模型可以通过深层网络和扩大感受野来建模这些长程依赖。
- 自回归函数可以显式地估计数据分布。给定之前像素的条件下,自回归模型可以预测下一个像素的概率分布。这意味着我们可以显式地计算整个图像的似然概率,从而可以用最大似然估计等方法来训练模型,更加稳定和可控。
- 自回归模型可以实现无条件和条件生成。无条件生成时,我们可以从空白图像开始,逐像素地采样生成新图像。条件生成时,我们可以固定一部分像素,对剩余像素进行采样,实现图像补全、修复等任务。这种灵活性是简单CNN不具备的。
- 自回归模型可以捕捉数据中的多模态性。对于一个给定的像素上下文,下一个像素的分布可能是多峰的,即存在多种可能的取值。自回归模型可以通过估计多峰概率分布来反映这种多模态性,而简单CNN通常只能预测单一的值。
- 自回归模型可以结合其他先验知识。我们可以在自回归模型中加入一些先验假设,如平移不变性、旋转不变性等,进一步提高模型的表示能力。这可以通过在网络中加入卷积层、池化层等结构来实现。
- 为什么要用自回归函数
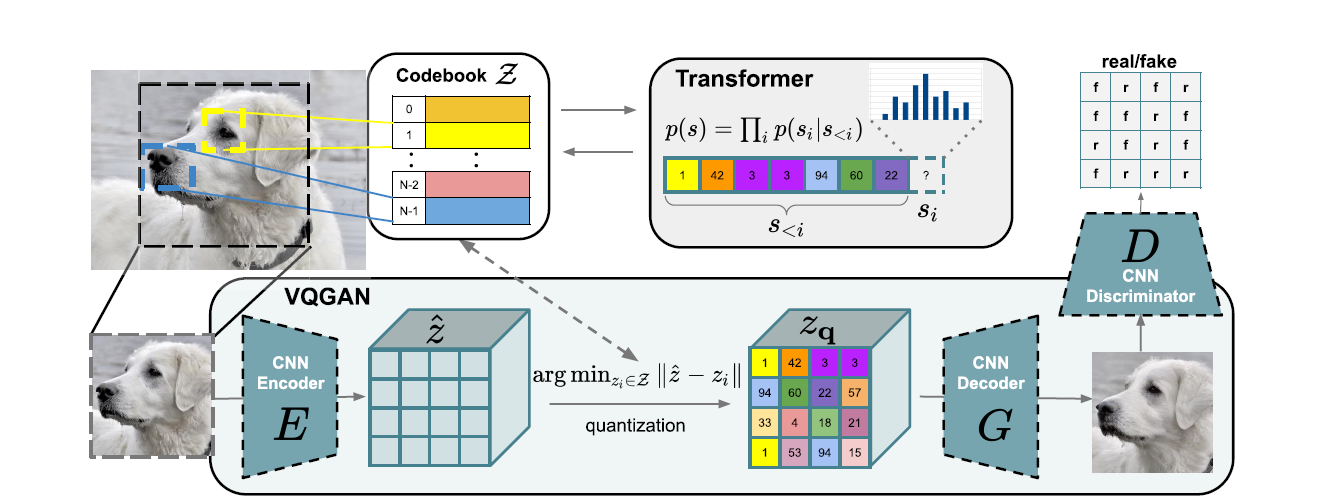
VQ-GAN
| 任务 | 数据集 | 图片分辨率 | Codebook大小 |
|---|---|---|---|
| 无条件图像生成 | ImageNet | 256×256 | 1024 |
| 无条件图像生成 | FacesHQ, FFHQ | 256×256 | 16384 |
| 无条件图像生成 | LSUN Churches & Towers | 256×256 | 1024 |
| 语义图像合成 | ADE20K | 256×256 | 4096 |
| 语义图像合成 | COCO-Stuff | 256×256 | 8192 |
| 语义图像合成 | S-FLCKR (Landscapes) | 256×256 | 1024 |
| 语义图像合成 | S-FLCKR (Landscapes) | 1024×1024 | 1024 |
| 深度图像合成 | RIN (Restricted ImageNet) | 256×256 | 1024 |
| 边缘图像合成 | ImageNet | 256×256 | 1024 |
| 姿态引导合成 | DeepFashion | 256×256 | 1024 |
| Class-conditional生成 | ImageNet | 256×256 | 16384 |
| Class-conditional生成 | RIN (Restricted ImageNet) | 256×256 | 1024 |
- 主体
- 提出了一种两阶段的图像合成方法,先用卷积网络VQ-GAN学习图像的紧凑表示(codebook),然后用Transformer对codebook进行建模,从而生成图像。这种方法可以显著降低Transformer处理的序列长度。
- VQ-GAN引入了感知损失和对抗训练,可以在高压缩率下得到高保真的重建图像。这为Transformer提供了信息丰富的视觉词汇。
- 在固定计算资源下,Transformer可以比卷积网络PixelCNN在学习到的离散表示上取得更好的建模效果。 所提出的方法可以用于多种条件图像合成任务,包括从语义分割图、深度图、边缘图、姿态等不同输入生成图像。
- 通过滑动窗口的方式,该方法可以生成高达1024×1024分辨率的图像。在人脸、教堂等数据集上可以生成高保真逼真的图像样本。
- 在ImageNet 256×256的class-conditional图像生成任务上,该方法优于之前的autoregressive模型如VQ-VAE-2,且推断速度更快。
- QA
- 为什么codebook是紧凑表示
- codebook中的每个entry(通常称为code)是一个固定长度的向量,用来表示图像的一个局部区域(patch)。相比原始像素空间,用离散的code表示图像可以显著降低信息冗余。
- 论文使用VQ-GAN以自监督的方式学习codebook。训练过程会最小化原始图像和重建图像(通过code解码得到)的感知差异。因此,学到的code能够尽可能保留原始图像的语义信息。
- codebook的大小(即code的数量)远小于图像像素的数量。论文中使用的codebook大小在512到16384之间,而高分辨率图像的像素数量可达百万级。
- 通过在Transformer中建模code的空间排布,而不是直接建模像素,可以将建模对象的数量从百万级降低到成千上万。这大大提高了建模高分辨率图像的计算效率。
- 实验表明,合适大小的codebook可以在信息压缩和重建质量之间取得很好的平衡。过小的codebook会导致重建失真,过大则会降低计算效率。
- 为什么codebook是紧凑表示
VQ-Diffusion
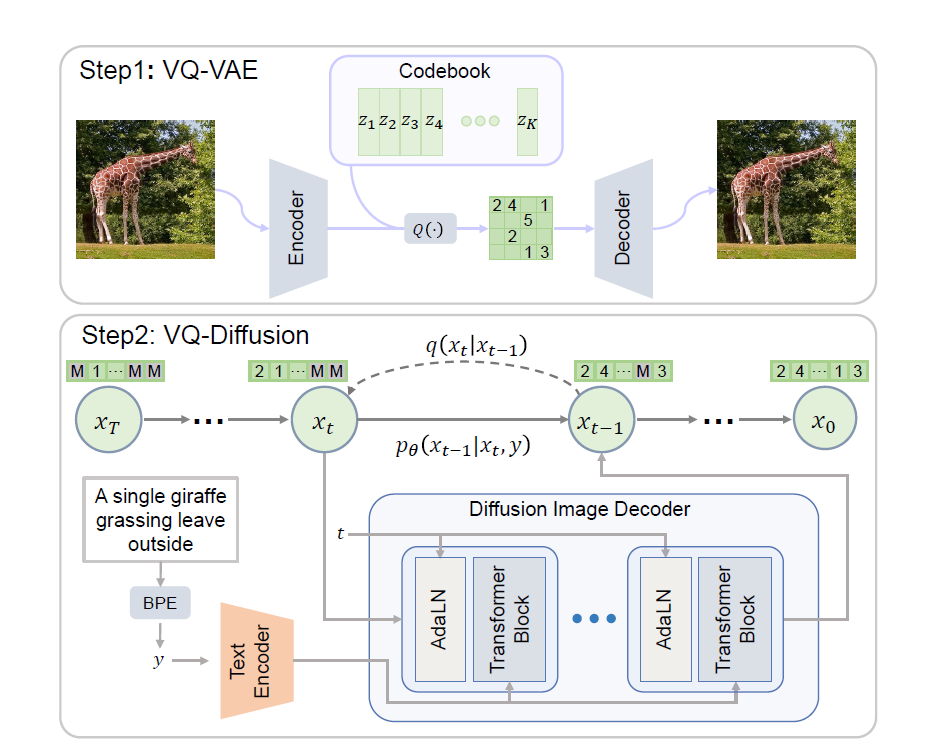
- 整体
- 先用VQ-VAE将图像压缩编码到离散的latent空间中,从而大大减少了图像的序列长度。
- 在离散的latent空间上应用conditional diffusion模型来建模latent codes的分布。通过逆向扩散过程,可以从纯噪声逐步去噪还原出符合文本描述的图像latent codes。
- 提出了一种mask-and-replace的diffusion策略,在每个去噪步骤中引入masked token,避免了生成误差的累积。
- 模型去除了自回归(auto-regressive)方法中存在的单向性偏差,同时生成速度更快
- 什么是masked token
- 在编码图像为离散tokens时,除了原有的visual token,还引入了一种特殊的[MASK] token。 在diffusion的前向过程中,每个visual token有一定概率γ被替换成[MASK]。同时有一个较小的概率β被随机替换成其他visual token。剩下的概率保持原始token不变。
- 模型训练时并不使用teacher forcing,而是刻意引入mask和随机替换的token,让模型学习在corruption较重的情况下也能预测出原始的visual token。
- 在逆向去噪过程中,[MASK] token起到显式指示噪声最重区域的作用。模型将更多地关注被mask的区域,在每一步根据上下文信息去预测[MASK]处原本的visual token,从而使去噪更加高效。
- 随机替换是为了避免模型过于关注[MASK],同时强迫模型去理解更广泛的上下文。而保留部分原始token则可以为恢复提供重要的先验信息。
- 这个机制是作者第一次使用的吗,还是从其他论文中借鉴出来的
- Mask-and-replace这个机制并非作者首创,而是借鉴了其他领域的思想:
- Masked language modeling(MLM): 这是近年来NLP领域非常流行的一种预训练范式,最早由BERT模型提出。MLM通过随机mask掉一部分输入token,训练模型根据上下文预测被mask掉的token,从而让模型学习到良好的语言表征。VQ-Diffusion中的mask思想可以看作是将MLM思想迁移到了视觉领域。
- Diffusion model: Diffusion过程最初由Sohl-Dickstein等人于2015年提出,近年来在CV领域受到越来越多的关注。传统的diffusion过程中仅仅使用了token replacement,VQ-Diffusion将其与mask策略相结合,是一个新颖的尝试。
- 其他工作: 之前也有一些将diffusion应用于离散数据的尝试,如Argmax Flow和D3PM,但它们主要关注文本生成或是低分辨率像素空间上的建模。将discrete diffusion应用于图像token空间并引入mask机制,VQ-Diffusion是最早的工作之一。
- Mask-and-replace这个机制并非作者首创,而是借鉴了其他领域的思想: