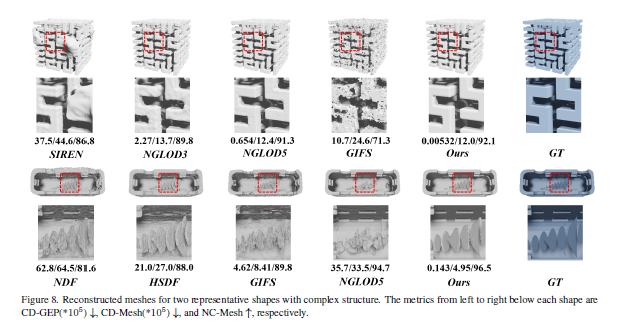
Unsigned Orthogonal Distance Fields: An Accurate Neural Implicit Representation for Diverse 3D Shapes
主要贡献
UODFs定义为沿三个正交方向(左右、前后、上下)的无符号距离场。每个空间点的UODFs值表示该点沿三个正交方向到形状表面的最短距离。
UODFs有三个主要特点:
由三个正交方向的无符号距离场组成
每个点的UODFs在每个正交方向上的一维导数绝对值等于1
相邻射线之间的UODFs值可能不连续
使用三个MLP神经网络分别拟合三个正交方向的UODFs。对每个射线等间隔采样点,每个采样点可直接估计其最近的表面点。
提出了一种从多个采样点估计表面点的方法,可以消除插值误差,只受神经网络拟合误差影响。最后融合三个方向估计的表面点得到最终结果。
在各种3D模型(封闭、开放、多层、组装等)上进行实验,UODFs的重建精度显著优于SDF、UDF等其他隐式表示方法,尤其是开放曲面和小尺寸点云重建。
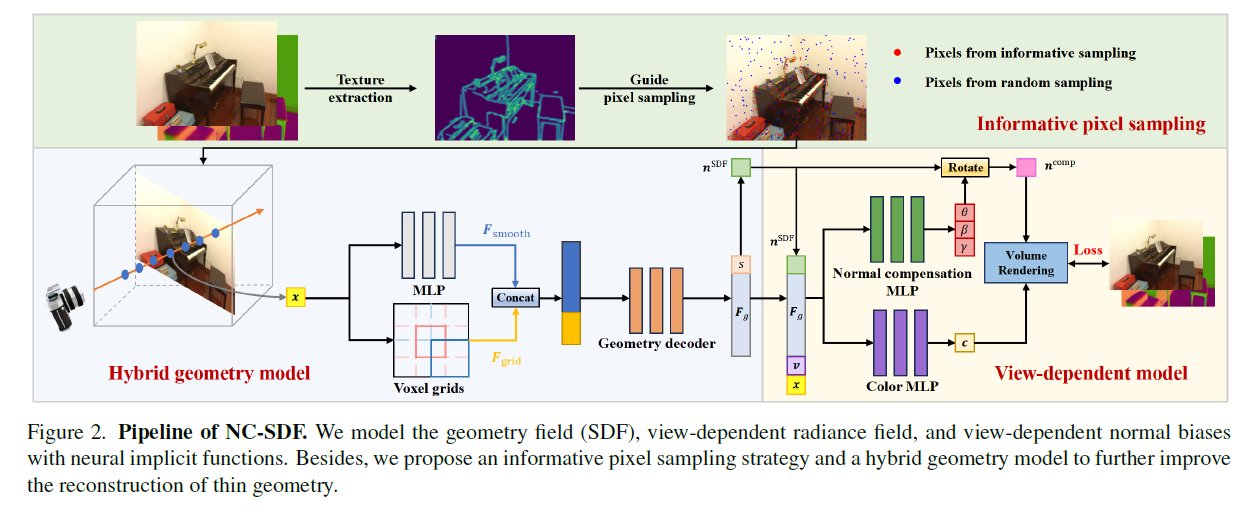
NC-SDF: Enhancing Indoor Scene Reconstruction Using Neural SDFs with View-Dependent Normal Compensation
提出了一种视角相关的法向补偿模型(view-dependent normal compensation model),用于解决单目几何先验在多视角下的不一致性问题。通过将法向先验中视角相关的偏差显式建模到场景的隐式表示中,并自适应地学习和校正这些偏差,可以有效缓解不一致监督带来的负面影响,提高重建的全局一致性和局部细节。
解决单目几何先验(尤其是法向先验)在多视角下不一致的问题
在之前的方法中,研究者通常直接将预测的单目法向图作为监督信号,引导隐式场景表示的优化。然而,由于预测网络是在单视角下进行估计的,所以预测的法向图往往与场景的真实法向不完全一致,并且这种偏差具有视角相关性。当多个视角的法向预测结果存在不一致时,会给隐式表示的优化带来困难,导致重建质量下降。
为了解决这个问题,论文提出将每个视角的法向偏差也建模到场景的隐式表示中。具体来说,他们设计了一个法向补偿模型,以视角方向为输入,预测对应视角下的法向补偿旋转角度。通过将这个旋转作用在隐式表示的法向上,就得到了经过补偿的法向。优化时,渲染得到的补偿后法向图与单目法向预测结果对齐,而不是直接用隐式表示的法向。
在训练过程中,法向补偿模型与颜色模型和几何模型一起联合优化。这种方式可以自适应地学习和校正不同视角下的法向偏差,使隐式表示更加鲁棒,从而提高重建质量。可视化结果表明,通过法向补偿,最终渲染得到的法向图与颜色图在不同视角下都更加一致,证明该模型能有效建模视角相关的法向偏差。
设计了一种信息量丰富的像素采样策略,通过优先采样信息量高的像素,使模型更加关注复杂的几何细节。
提出了一种基于特征融合的混合几何建模方法,利用MLP的感应平滑性来确保平滑表面,同时利用体素网格提供的高频编码来捕捉精细几何。
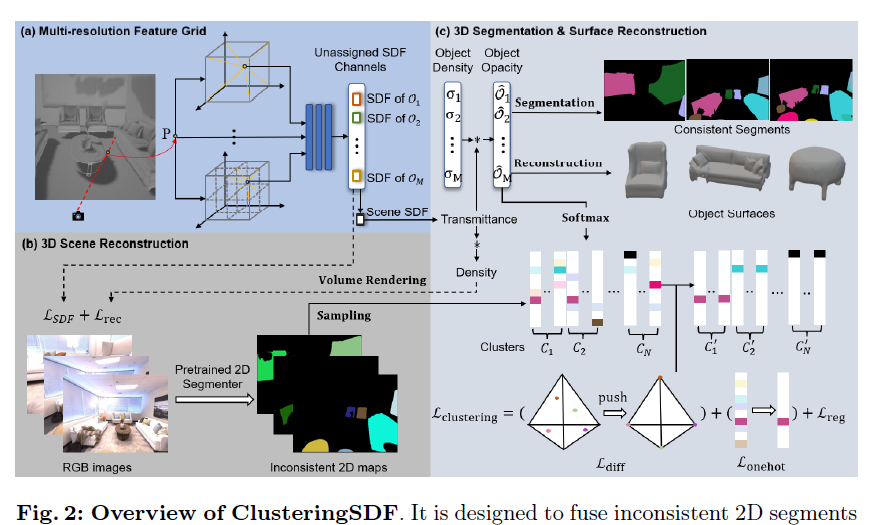
ClusteringSDF: Self-Organized Neural Implicit Surfaces for 3D Decomposition
提出了一种新颖的方法ClusteringSDF,可以将2D机器生成的分割标签融合到3D中,同时通过神经隐式表面重建(SDF)来重建场景中物体的表面。
预训练的2D分割模型Mask2Former生成2D分割标签作为弱监督信号
用于监督的分割标签来自Mask2Former,而对于定量指标,我们将预测结果与groundtruth标签进行了比较
有助于提升3D分割的性能
设计了一种高效的聚类机制,用于对齐这些多视图不一致的标签,生成一致的3D分割表示。该方法通过归一化将聚类中心限制在一个单纯形内,从而实现高效聚类。
在没有真值标签监督的情况下,ClusteringSDF保持了场景和物体的对象组合表示。
实验结果表明,该模型在渲染一致的3D分割标签方面达到了最先进的性能。同时,与最新的基于NeRF的3D分割方法相比,ClusteringSDF的训练时间不到四分之一。
展示了该方法完全从不一致的2D标签重建场景中单个物体表面的能力。
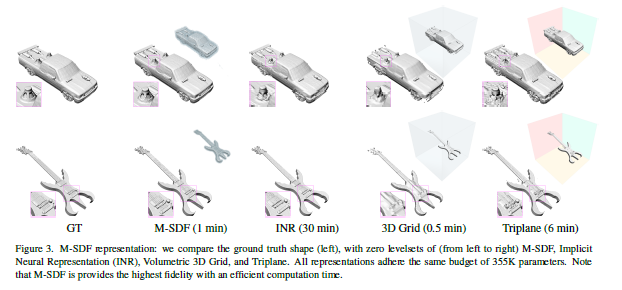
Mosaic-SDF for 3D Generative Models
提出了一种新的3D形状表示方法Mosaic-SDF(M-SDF),可以近似任意形状的SDF。M-SDF使用一组局部网格来近似SDF,这些网格分布在形状边界附近。该表示法具有以下优点:
预处理效率高:可以快速计算大规模数据集中每个形状的M-SDF表示,计算过程易于并行化。
参数效率高:只在形状边界附近覆盖空间,提供了良好的近似能力和参数数量的平衡。
简单的张量结构:M-SDF是一个简单的矩阵形式,与Transformer等强大的神经网络架构兼容。
作者利用M-SDF训练了基于Flow Matching的3D生成模型,在ShapeNetCore-V2数据集上进行了类条件生成,在约60万个形状-文本对上进行了文本到3D的生成,取得了很好的效果。
与其他常见的3D表示方法相比,M-SDF在近似精度、计算效率、参数效率等方面具有优势。
3d ,
AI
May 13, 2024