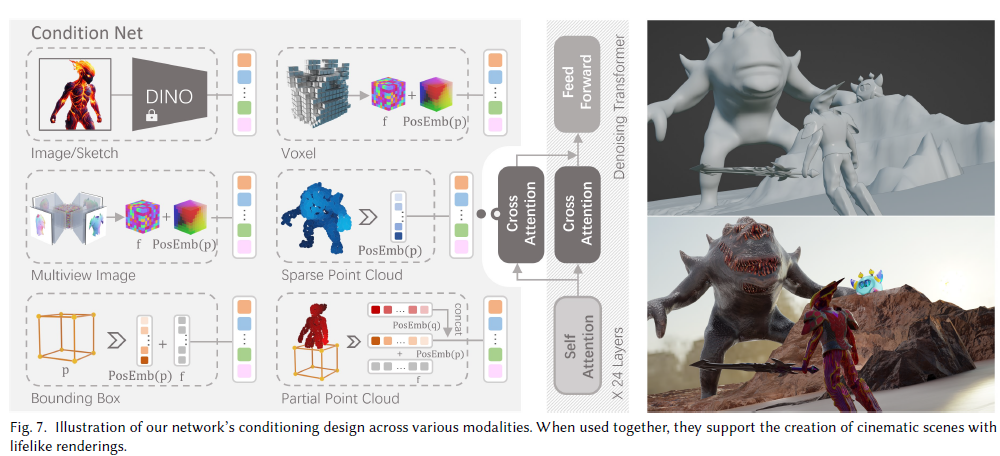
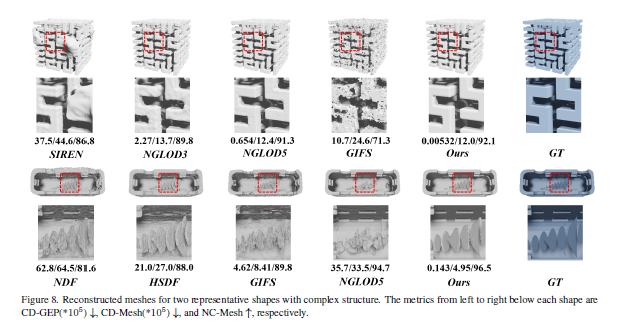
Sora: The paper you need to read
Papers
- Dall-e 3
- Vq-vae
- DiT
- Generating Long Videos of Dynamic Scenes
- VideoGPT: Video Generation using VQ-VAE and Transformer
- Imagen Video: High Definition Video Generation with Diffusion Models
- Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
- Photorealistic Video Generation with Diffusion Models
- ViViT: A Video Vision Transformer
- 长上下文训练
- Lumiere: A Space-Time Diffusion Model for Video Generation
- magvit2
- video vae encoder-decoder
- Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
- Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
- VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
- VideoPoet: A Large Language Model for Zero-Shot Video Generation
- 分辨率上不去