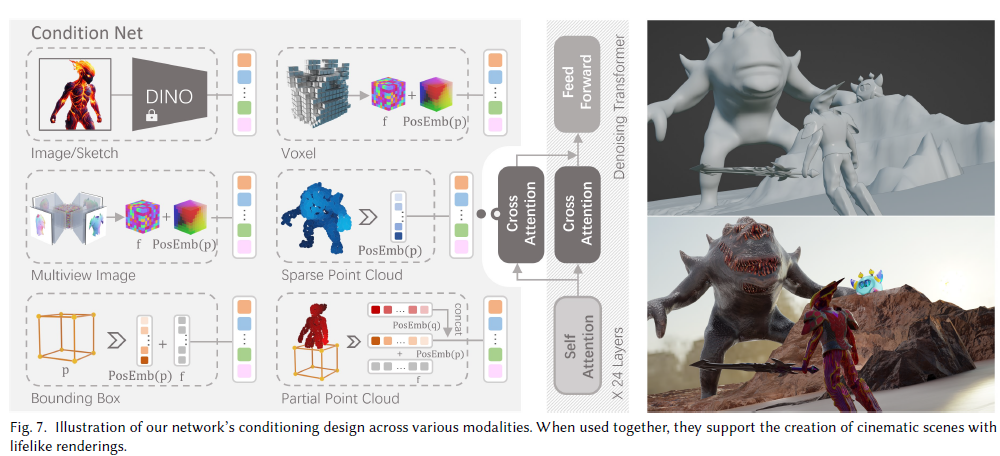
OpenClip
OpenClip, 对齐文本和图像的隐空间

- OpenClip
- 对比学习
- 对比学习(Contrastive Learning)是一种自监督学习方法,旨在学习数据的通用表示,以便在下游任务中可以更好地利用这些表示。其核心思想是通过最大化相似样本对之间的相似度,同时最小化不相似样本对之间的相似度,来学习数据的特征表示。具体而言:
- 正样本对:对同一实例的两个随机增强版本(如图像的裁剪、翻转、颜色变化等)构成正样本对,模型需要学习将它们的特征表示拉近。
- 负样本对:将不同实例的特征表示作为负样本对,模型需要将它们的特征表示拉远。
- 对比损失:通过一个对比损失函数(如InfoNCE损失)来优化上述目标,使相似样本对的特征表示相近,不相似样本对的特征表示相异。
- 常见的对比损失函数
- InfoNCE损失(Information Noise-Contrastive Estimation): InfoNCE损失源自NCE (Noise-Contrastive Estimation),是一种常用的对比损失函数。对于一个正样本对(i,j),InfoNCE损失定义为: $L_{i,j} = -\log \frac{\exp(sim(z_i,z_j)/\tau)}{\sum_{k=1}^N \exp(sim(z_i,z_k)/\tau)}$ 其中,$z_i$和$z_j$是正样本对的特征表示,$z_k$是负样本的特征表示,$sim$是相似度度量(如点积),$\tau$是温度超参数,N是负样本的数量。
- Triplet损失(Triplet Loss): Triplet损失通过构建三元组(anchor, positive, negative)来优化样本间的相对距离。其目标是anchor与positive之间的距离小于anchor与negative之间的距离。数学表达为: $L = \max(d(a,p) - d(a,n) + \mathit{margin}, 0)$ 其中,$d$是距离度量(如欧氏距离),$\mathit{margin}$是一个正的边界值。
- NT-Xent损失(Normalized Temperature-scaled Cross Entropy Loss): NT-Xent损失是SimCLR中使用的损失函数,类似于InfoNCE损失,但进行了标准化和对称化处理。对于一对正样本(i,j),NT-Xent损失定义为: $l_{i,j} = -\log \frac{\exp(sim(z_i,z_j)/\tau)}{\sum_{k=1}^{2N} \mathbf{1}{[k \neq i]} \exp(sim(z_i,z_k)/\tau)}$ 其中,$\mathbf{1}{[k \neq i]} \in {0, 1}$是指示函数,N是批次大小。NT-Xent损失在批次内对所有样本对进行计算,并进行对称化处理。
- Contrastive Cross Entropy损失: 对比交叉熵损失将对比学习问题看作是二分类问题,正样本对应标签1,负样本对应标签0。损失函数定义为: $L = -\frac{1}{N} \sum_{i=1}^N \left( y_i \cdot \log(\hat{y}_i) + (1-y_i) \cdot \log(1-\hat{y}_i) \right)$ 其中,$y_i$是样本对的真实标签,$\hat{y}_i$是模型预测的相似度。
- 常见的对比损失函数
- 对比学习可以应用于各种类型的数据,如图像、文本、语音等。一些著名的对比学习方法包括:
- SimCLR (Simple Framework for Contrastive Learning of Visual Representations)
- MoCo (Momentum Contrast for Unsupervised Visual Representation Learning)
- CLIP (Contrastive Language-Image Pre-training)
- 在CLIP中,通过对比学习,模型可以学习到图像和文本的统一表示空间,在此空间中语义相似的图像和文本更加靠近。这种对比学习方式使得CLIP模型具有良好的零样本和少样本学习能力。
- 多模态embedding
- 如图所示,给定一个 Batch 的 N 个 (图片,文本) 对,图片输入给 Image Encoder 得到表征 I1, I2, …, IN ,文本输入给Text Encoder得到表征 T1, T2, …, TN, 然后通过“对比学习”,找到图像和文字的相似关系。对于图中列出的N*N个格子,只需计算每个格子上对应的向量点积(余弦相似度)。由于对角线上的图片-文字对是真值,希望对角线上的相似度可以最大,据此可设置交叉熵函数,来求得每个batch下的Loss。
- 预训练
- 视觉预训练
- 通过对比学习使得同一张图像的不同裁剪或变换间距离更近,不同图像间距离更远。这样模型就能学习有区分度的视觉特征表示
- 视觉-语言预训练
- 对比学习的方法,使得相同含义的不同图像和文本之间的距离更近,而不同含义的图像和文本之间的距离更远
- 视觉预训练
- Zero Shot预测
- 首先,创建一个标签全集,如图中(2)所示,并得到每一个标签的特征向量
- 然后,取一张图片,如图中(3)所示,过Image Encoder后得到该图片的特征向量
- 最后,计算图片向量和文字向量间的相似度,取相似度最高的那条label即可。
- 优势/劣势
- 优势
- 无监督或弱监督的学习方法
- 泛化能力强
- 可解释性好
- 劣势
- 文字标签是个闭集:模型预测一张新的图像,只能从已有的标签集合中找出最相似的,不能预测一个新标签。
- 优势
- 数据集
- LAION-5B 数据集,包含 58 亿个密切相关的图像-文本对
- 对比学习
Stable diffusion 对比
| 组件 | SDXL | SD 1.4/1.5 | SD 2.0/2.1 |
|---|---|---|---|
| UNet 参数 | |||
| 参数量 | 2.6B | 860M | 865M |
| Transformer blocks | [0, 2, 10] | [1, 1, 1, 1] | [1, 1, 1, 1] |
| Channel mult. | [1, 2, 4] | [1, 2, 4, 4] | [1, 2, 4, 4] |
| 文本编码器 | |||
| 模型 | CLIP ViT-L & OpenCLIP ViT-bigG | CLIP ViT-L | OpenCLIP ViT-H |
| Context dim. | 2048 | 768 | 1024 |
| Pooled text emb. | OpenCLIP ViT-bigG | N/A | N/A |
| VAE | |||
| Reconstruction | 优于 SD 1.x/2.x | - | - |
| 训练设置 | |||
| 分辨率 | 256->512->1024 | 256/512 | 512/768 |
| Aspect Ratios | 支持多种 | 正方形 | 正方形 |
| Conditioning | 大小,裁剪,长宽比 | N/A | N/A |
| Refinement | 额外的refiner模型 | - | - |
Openclip 模型对比
| Model name | Batch size | Samples seen | Text Params | Image params | ImageNet top1 | Mscoco image retrieval at 5 | Flickr30k image retrieval at 5 |
|---|---|---|---|---|---|---|---|
| OpenAI CLIP L/14 | 32k | 13B | 123.65M | 303.97M | 75.4% | 61% | 87% |
| OpenCLIP H/14 | 79k | 32B (16 epochs of laion2B) | 354.0M | 632.08M | 78% | 73.4% | 94% |
| OpenCLIP G/14 | 160k | 32B +unmasked fine-tune (details below) | 694.7M | 1844.9M | 80.1%* | 74.9% | 94.9% |
| CoCa | 66k | 33B | 1100M | 1000M | 86.3%** | 74.2% | 95.7% |
OpenCLIP G/14模型的ImageNet top1精度有个星号,说明该数值可能有些特殊情况。 CoCa模型的ImageNet top1精度有两个星号,也表示该数值的测试条件可能与其他模型不完全一致。