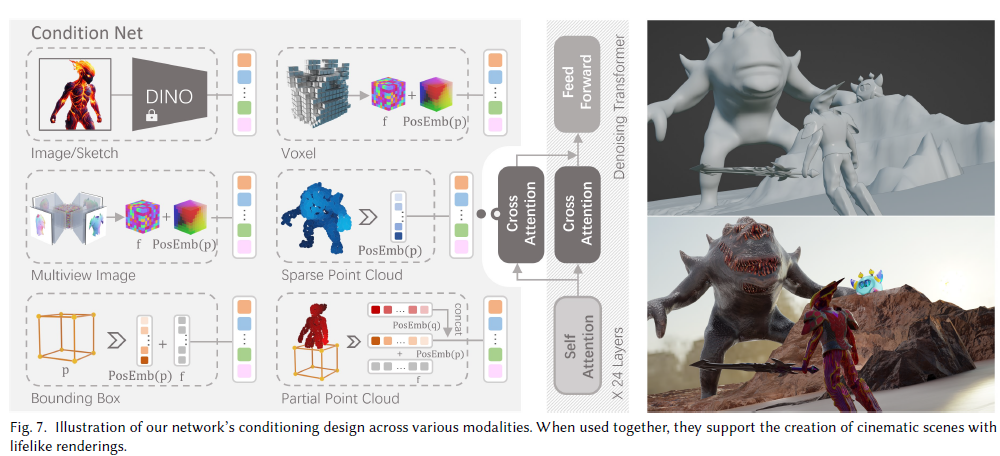
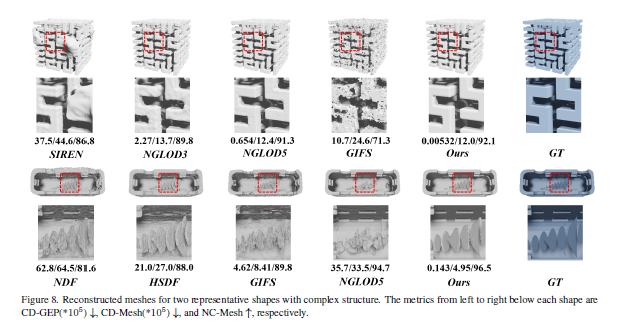
Dalle3
Dalle3
- Improving Image Generation with Better Captions - dalle3
- 关于生成模型
- 基础模型:先在图文对数据集上预训练了一个类似于语言模型的图像描述生成器。输入为图像的CLIP编码和已生成的字符,输出为下一个字符的概率分布。这样模型就学会了根据图像内容生成与之匹配的描述文本。
- 短句微调:在此基础上,作者又准备了一个小规模的数据集,其中的描述只关注图像的主要内容。用这个数据集微调上一步的模型,使其倾向于生成简洁的描述文本。这一步得到的模型被称为”short synthetic captions”。
- 长句微调:类似地,作者再准备一个小规模的长描述数据集,其中的描述不仅涉及图像主体,还包含了背景、数量、颜色等丰富的细节。再次用这个数据集微调,得到的模型称为”descriptive synthetic captions”,可以生成详尽的描述。
- 关于提高文本到图像生成系统能力
- 现有的文本到图像模型在跟随详细的图像描述指令方面存在困难,经常会忽略或混淆文字中的含义。作者认为这个问题源自训练数据中的图像描述文本质量较差,存在噪声和不准确性。
- 为了解决这个问题,作者训练了一个定制的图像描述生成模型,用它重新为训练图像生成了更详细、准确的人工描述文本。然后用这些高质量的合成描述来训练文本到图像模型。
- 实验结果表明,用合成的描述训练可以显著提高模型对输入文本的理解和表达能力。基于这个发现,作者构建了一个新的系统DALL-E 3。
- 在对DALL-E 3进行评估时,考察了它在理解指令、生成连贯图像、图像美感等方面的表现,结果优于目前的一些竞争模型。作者还公开了评估所用的样本和代码,以推动后续研究进一步优化文本到图像模型的这些重要能力。
- 论文还讨论了当前方法的局限性,例如DALL-E 3在空间感知、生成文本、理解特定概念等方面仍有不足,未来可通过改进图像描述生成器等方式来提升。同时还分析了系统可能带来的风险,并在附录中详细阐述了安全性和偏差的缓解措施。
- 使用的文本编辑器
- T5 (Text-to-Text Transfer Transformer)
- 即过度拟合数据集中的分布规律。
-
Likelihood models like our text-to-image diffusion models have a notorious tendency to overfit to distributional regularities in the dataset. For example, a text-to-image model that is trained on text that always starts with a space character will not work properly if you try to perform inference with prompts that do not also start with that space.
-
- 关于生成模型
- Improving Image Captioning with Better Use of Captions
- 目标
- 使用高度描述性的生成的caption上训练文生图模型,可以显著提高文本到图像模型的提示跟随能力
- 重点评估了DALL-E 3在高度描述性生成标题的训练下改进的提示跟踪。它不涉及DALL-E 3模型的训练或实现细节。
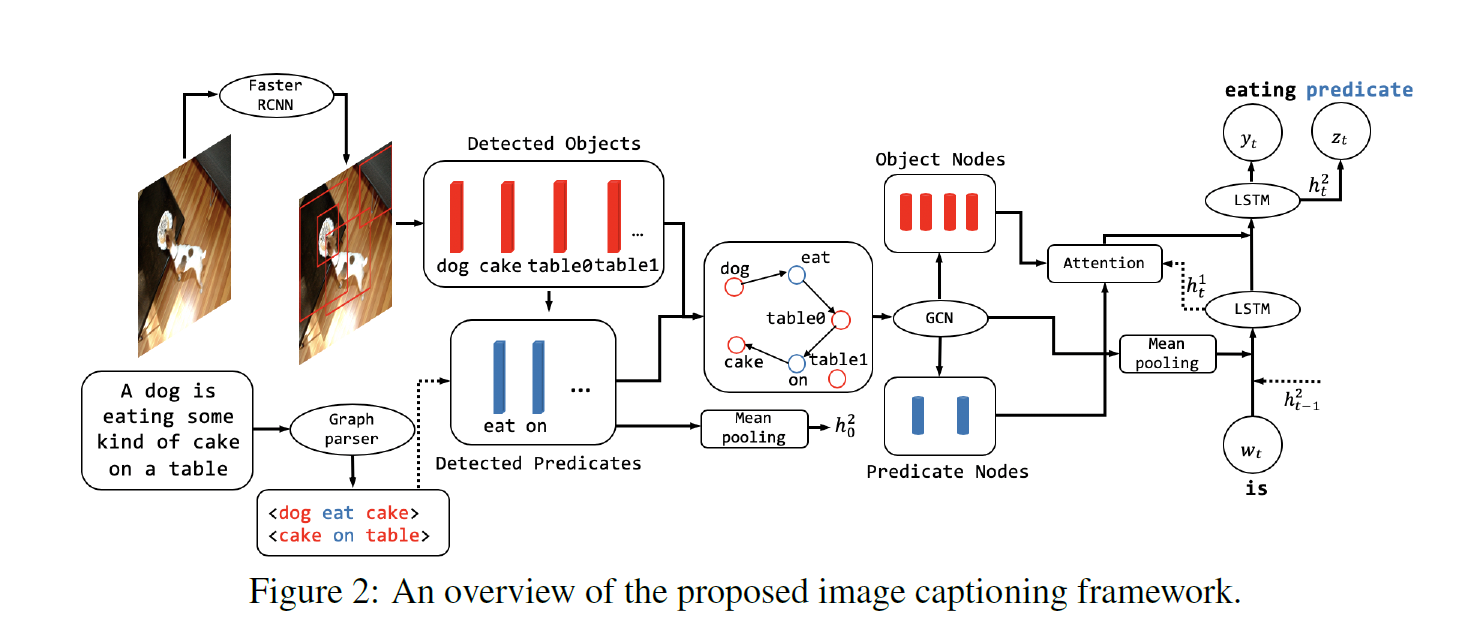
- 这篇论文提出了一个新的图像描述生成框架,主要有以下几个创新点:
- 利用图像描述文本构建可视化关系图(Caption-Guided Visual Relationship Graph, CGVRG)。之前的方法使用预训练的视觉关系检测模型构建关系图,但这些模型常忽略一些对描述任务很重要的关系。本文使用图像描述文本提取三元组(主体-谓词-宾语),然后用弱监督的多示例学习方法将三元组中的谓词与图像中的区域配对,以此构建面向描述任务的可视化关系图。
- 通过图卷积操作,将CGVRG中节点的视觉和文本特征融合,增强节点表示能力。
- 图卷积$h_i^{(l+1)} = \sigma\left(\sum_{j\in \mathcal{N}(i)} \frac{1}{c_{ij}} W^{(l)} h_j^{(l)}\right)$
- 在描述生成阶段,提出了一个多任务学习模块。模型在生成每个单词的同时,还预测该单词是主体、谓词还是其他。这种方式可以帮助模型判断在生成每个单词时,应该着重参考CGVRG中的哪类节点信息。