CLAY: A Controllable Large-scale Generative Model for Creating High-quality 3D Assets
主要贡献
CLAY的核心是一个在大规模3D数据上预训练的1.5亿参数的生成模型。该模型使用多分辨率VAE对几何形状进行编码,并用一个极简的latent diffusion transformer进行几何生成。
将多分辨率VAE和极简的latent diffusion transformer结合,并在1.5亿参数量级上实现了模型的高效训练
为了训练该大规模模型,作者提出了一个数据标准化流程,包括重新网格化来统一不同来源的3D数据格式,以及利用GPT-4V对数据自动标注。
在几何生成的基础上,CLAY还可以合成PBR材质贴图,实现逼真的渲染效果。作者训练了一个多视角材质扩散模型来高效地生成高分辨率的漫反射、粗糙度等贴图。
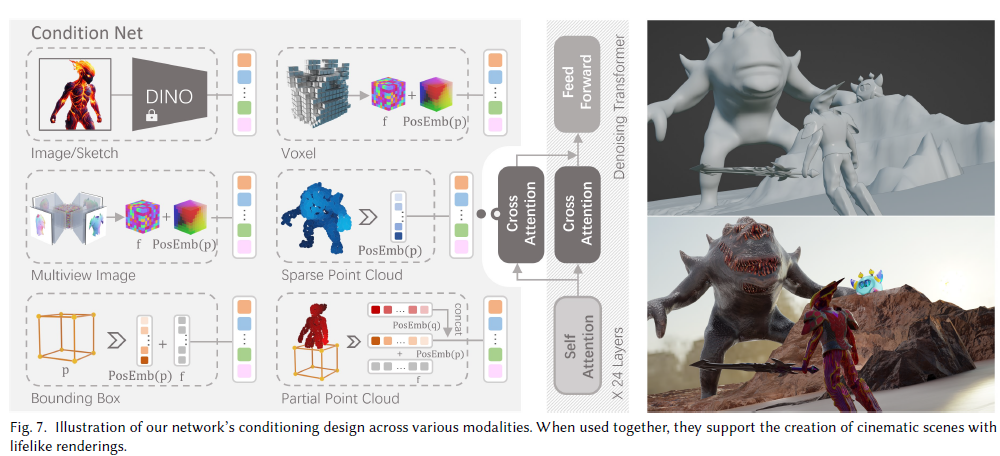
CLAY支持低秩适应(LoRA)微调以及多种条件生成,可以根据草图、体素、包围盒、点云等多种输入控制生成。
SketchDream: Sketch-based Text-to-3D Generation and Editing
同时使用单视角手绘草图和文本提示作为输入,生成高质量3D模型的端到端系统。生成的结果既能忠实于输入的草图,也能满足文本的描述。
利用深度引导的扭曲策略来建立视角间的空间对应关系,并使用3D注意力模块来确保不同视角下生成图像的3D一致性
粗到精的两阶段编辑框架
支持对重建或生成的NeRF进行局部细节编辑
并采用3D注意力控制模块确保3D一致性
对于新视角图像,最近视角的输入是通过深度扭曲得到的草图,其他视角的输入是空白图像。为了确保不同视角下生成图像的3D一致性,该模块采用了MVDream中的3D注意力机制
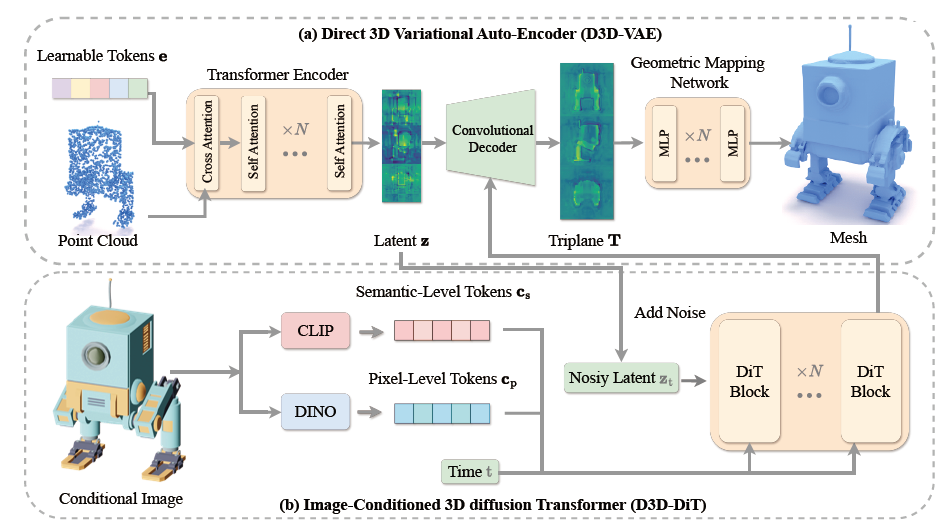
提出了D3D-VAE模型,可以将高分辨率的点云编码到一个紧致的3D latent空间中。不同于以往方法使用渲染图像作为监督信号,D3D-VAE直接对解码后的几何形状进行监督,采用了半连续的表面采样策略,更好地保留了3D形状的细节
在D3D-VAE中,编码器将点云压缩到三平面latent空间,解码器再将低分辨率的latent表示上采样到高分辨率的三平面特征图,最后通过可学习的MLP将三个特征图映射为occupancy场,以重建3D形状。
提出了D3D-DiT扩散模型,可以根据输入的参考图像在3D latent空间中生成与之一致的3D模型。D3D-DiT专门设计了像素级和语义级两个层面的图像对齐模块,使生成的3D模型能在局部细节和整体语义上与输入图像保持一致。
采用了显式的triplane latent表示,比隐式编码更利于3D信息的保留;提出的像素级和语义级图像条件对齐模块有助于提升3D生成的细节和一致性。
Blender GPT; SceneCraft: An LLM Agent for Synthesizing 3D Scene as Blender Code
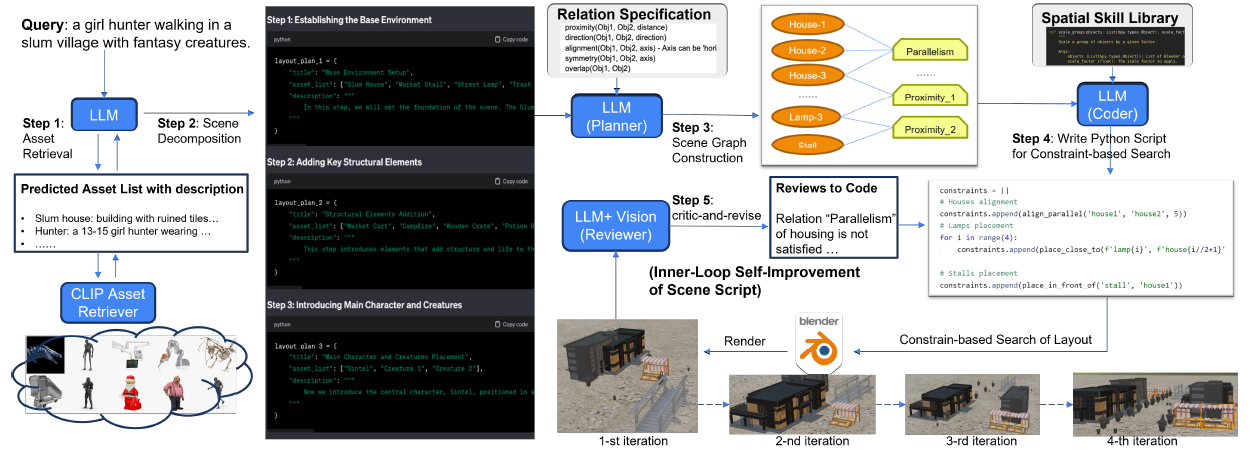
使用一个双循环优化流程:
内循环针对每个场景进行优化。给定文本查询,LLM规划器构建一个场景图,详细说明场景中资产之间的空间关系。然后SceneCraft基于图编写Python脚本,将关系转化为数值约束条件。渲染图像后,利用GPT-V等多模态LLM分析图像,判断是否与文本描述匹配,如果不匹配则识别出问题所在并迭代优化脚本。
外循环则动态扩展SceneCraft的”空间技能”库。它回顾内循环中约束脚本的渐进式变化,识别出其中通用的代码模式并整合到库中,从而实现不依赖昂贵的LLM参数调优的持续自我完善。
SceneCraft只需要在20个带有ground-truth约束的合成查询上进行双循环优化,就能开发出一个鲁棒的技能库。相比传统的模型微调,这种方法更加高效和可适应性强。
在合成数据集和真实世界的Sintel电影数据集上的实验表明,SceneCraft能比现有的LLM智能体如BlenderGPT更高效准确地根据文本生成复杂3D场景。定量上,SceneCraft在CLIP相似度、满足约束条件的比例等指标上大幅超越基线;定性上,SceneCraft生成的场景和视频也更准确地捕捉到了文本描述的细节。
Unique3D: High-Quality and Efficient 3D Mesh Generation from a Single Image
Unique3D能够在30秒内从单视角图像高效生成高质量的3D网格,具有目前最先进的生成保真度和泛化能力。
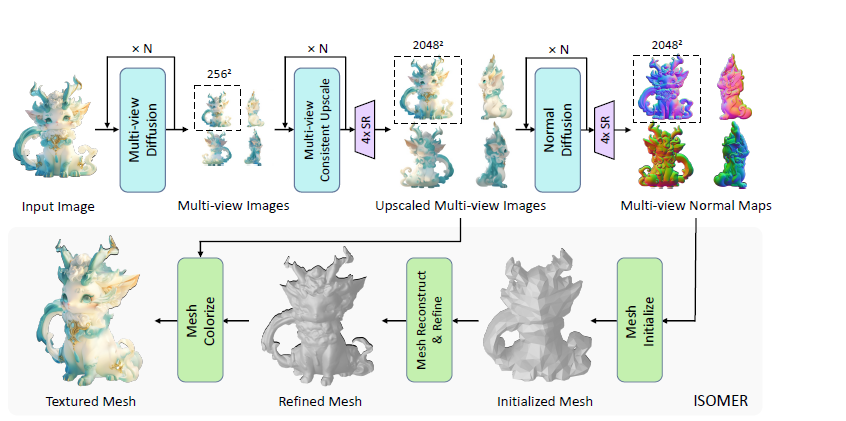
提出了一种多级上采样策略,可以逐步提高生成的多视图图像和法线贴图的分辨率。
设计了一种新的即时一致网格重建算法ISOMER(Instant and Consistent Mesh Reconstruction),可以从RGB图像和法线贴图中重建几何细节和纹理丰富的3D网格。
初始网格估计(Initial Mesh Estimation):直接从正面和背面视图估计目标形状的初始网格拓扑结构。将正面视图的法线贴图积分得到深度图,映射每个像素到空间位置,从而分别从物体的正面和背面视图创建网格模型。通过泊松重建将两个模型无缝连接,并简化成2000个面作为初始网格。
从粗到细的网格优化(Coarse-to-Fine Mesh Optimization):通过最小化基于掩码和法线的损失函数,迭代优化网格模型逼近目标形状。每次优化时先进行可微渲染计算损失和梯度,再根据梯度移动顶点,最后通过边坍缩、边分裂和边翻转校正网格。数百次迭代后网格收敛到目标形状的粗略近似。引入了一个膨胀正则化(Expansion Regularization)来避免法线监督下网格塌缩。
多视图不一致性的显式优化目标(ExplicitTarget for Multi-view Inconsistency):由于野外图像的多视图不一致性,没有完美匹配所有视角的解。因此提出了一种为每个顶点分配唯一优化目标的方法,更加鲁棒地引导优化方向。ExplicitTarget将可见视图的加权平均作为每个顶点颜色的优化目标,权重由投影面积和法线预测置信度决定。
在单图像到3D任务上进行了大量实验,证明了该方法的有效性和生成保真度,为3D生成AI在现实应用中开辟了新的可能性。
方法主要分为3个步骤:
利用多视图扩散模型从输入图像生成4个正交多视图图像及其法线贴图,并通过多级上采样将其分辨率提升。
利用ISOMER算法从高分辨率RGB图像和法线贴图即时重建出高质量一致的3D网格,该算法充分整合了颜色和几何先验。
在生成的网格上进行着色,得到最终的带纹理3D模型。
3d ,
AI
June 30, 2024