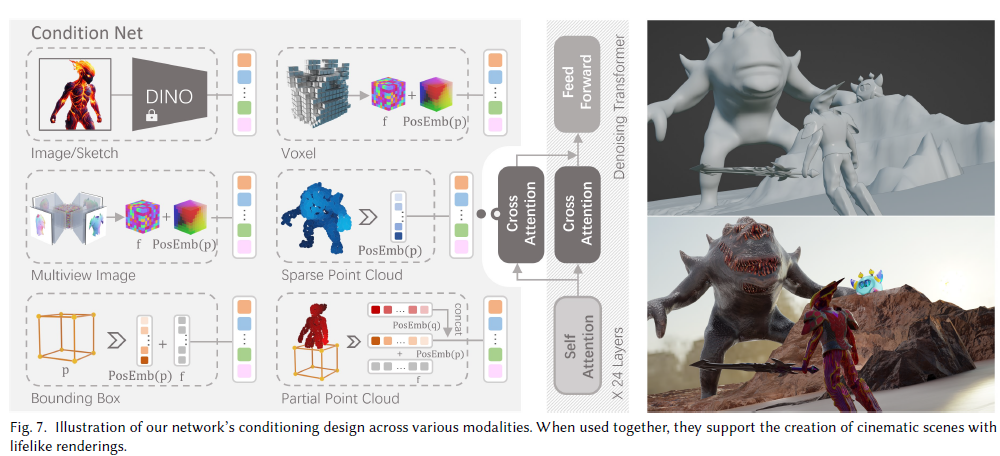
MeshNet Latent space
Introduction
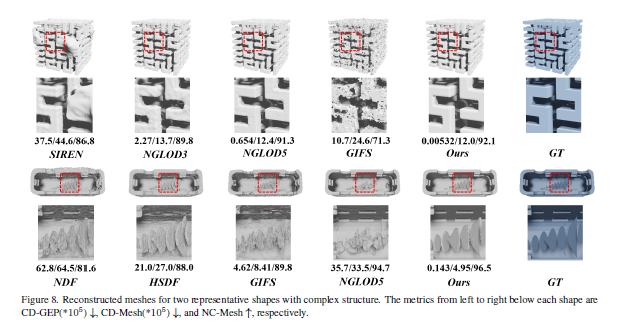
DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation
text to 3d
- 3dfy
- text to 3d, image to 3d
- objects
- interiors: table lamps、sofa、table、ottoman、cutlery
- gaming:sword、shield、axes
- 提供API
- 面像对象:GTA
- 架构和技术方案(没有具体写参照的论文)
- DreamFusion - google
- 平均1.5小时
- 文本->2D图像->优化为Nerf
- Score Jacobian Chaining(目前几乎所有的零样本开放域文生 3D 工作所使用的算法)
- 问题:过于平滑、过饱和现象严重

- stable-dreamfusion
- python + cuda
-
A pytorch implementation of the text-to-3D model Dreamfusion
- prolificdreamer - 清华 2023
- Paper
- Code: release soon
- DataSet: LAION-5B
- A dataset consisting of 5.85 billion CLIP-filtered image-text pairs, featuring several nearest neighbor indices, an improved web-interface for exploration and subset generation, and detection scores for watermark, NSFW, and toxic content detection.
- VSD(Variational Score Distillation)变分得分蒸馏 + Nerf
- 将3D优化转为2D图像概率分布
- 解决了 DreamFusion 所提 SDS 算法的过饱和、过平滑、缺少多样性等问题

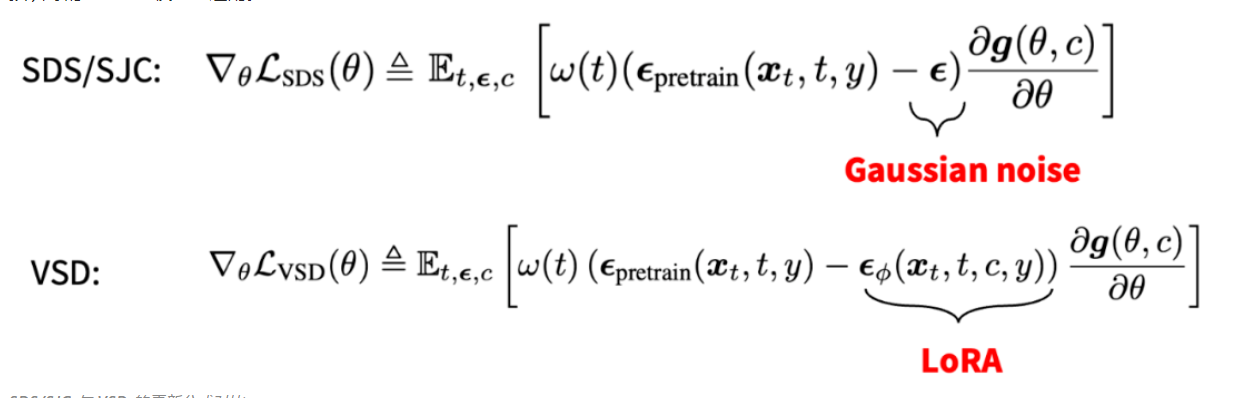
- 开发者社区 机器之心 文章 正文 无需任何3D数据,直接文本生成高质量3D内容,清华朱军团队带来重大进展 - 阿里云
- Magic3D - Nvidia
- 平均40分钟
- 一句话生成3D模型!NVIDIA提出Magic3D:高分辨率文本到3D内容创建 - CSDN
- Magic3D提出了一个两阶段的优化框架,通过使用不同分辨率的扩散先验进行粗到精的优化过程。这使得Magic3D能够生成更高分辨率的几何体和纹理。而DreamFusion在这方面存在限制,无法获取高分辨率的几何体和纹理。
- Magic3D采用了一种多分辨率哈希网格编码架构,使用具有32个隐藏单元的单层MLP来预测RGB颜色、体积密度和法线。同时,Magic3D还引入了密度基础剪枝方法来稀疏表示,并通过密度偏置来优化粗糙神经场表示。

- Shap-E: Generating Conditional 3D Implicit Functions - 2023 - OpenAI
- dataset:貌似是私有的
- 隐式空间的编码器训练
- 点云->点卷积->交叉注意力->patch->隐式空间的编码表示
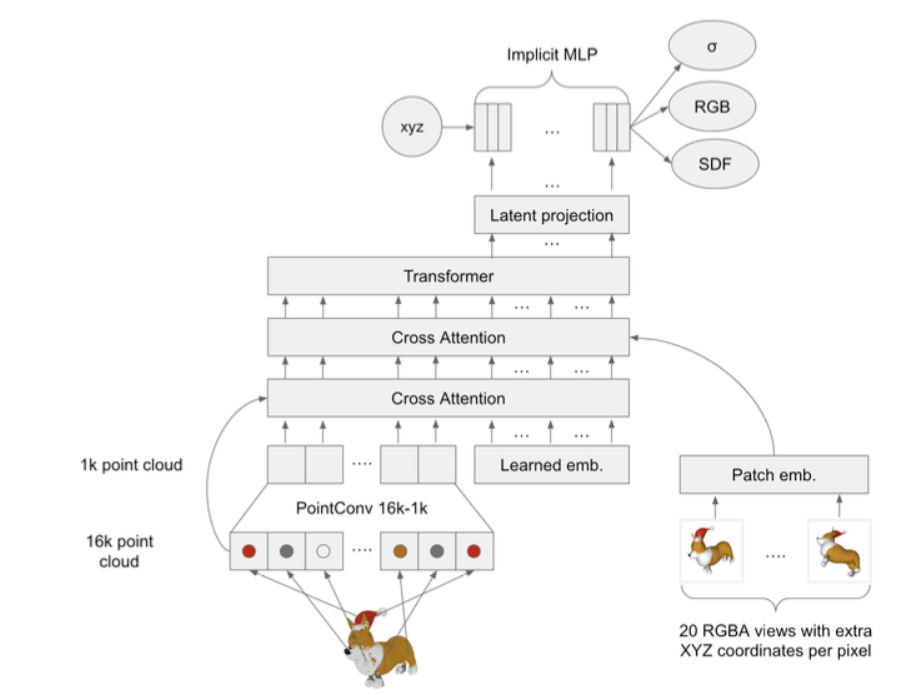
- Latent Diffusion 条件扩散模型
- Point-E: A System for Generating 3D Point Clouds from Complex Prompts - OpenAI
- text -> point cloud -> mesh(based on sdf)
- 基于文本生成合成视图,基于合成视图生成粗糙的点云,最后根据低分辨率点云和合成视图生成精细的点云。
- 条件扩散模型